Setting the Scene
Overview
Teaching: 10 min
Exercises: 0 minQuestions
What are we teaching in this course?
What motivated the selection of topics covered in the course?
Objectives
Setting the scene and expectations
Making sure everyone has all the necessary software installed
Introduction
So, you have gained basic software development skills either by self-learning or attending, e.g., a novice Software Carpentry course. You have been applying those skills for a while by writing code to help with your work and you feel comfortable developing code and troubleshooting problems. However, your software has now reached a point when you have to use and maintain it for prolonged periods of time, or when you have to share it with other users who may apply it to different kinds of tasks or data. Perhaps your projects now involve more researchers (developers) and users, and more collaborative development effort is needed to add new functionality while ensuring that previous features remain functional and maintainable.
This single-day course is dedicated to basic software testing and profiling tools and techniques. Both testing and code profiling are essential stages of the development of large software projects, however, in smaller academic software we often skip them for the sake of speeding up the work. While reasonable when we are dealing with scripts that are only a few hundred lines long, this approach fails us once we begin developing more complicated and computationally heavy software. It is particularly important for collaborations in which the code produced by one developer can break the code written by someone else.
The goals of software testing are:
- to make sure that the developed code satisfies the requirements, i.e. does what it’s supposed to do;
- to check that it produces the correct outputs for any valid input;
- to ensure that the user is warned when the input data is invalid.
Code profiling, on the other hand, is the process of measuring how much and which resources the software uses. The most common resources measured are time, memory and CPU load. Profiling is necessary when developing computationally expensive code or software that will be applied to large volumes of data.
The course uses a number of different software development tools and techniques interchangeably as you would in a real life. We had to make some choices about topics and tools to teach here, based on established best practices, ease of tool installation for the audience, length of the course and other considerations. Tools used here are not mandated though: alternatives exist and we point some of them out along the way. Over time, you will develop a preference for certain tools and programming languages based on your personal taste or based on what is commonly used by your group, collaborators or community. However, the topics covered should give you a solid foundation for producing high-quality software that is easier to sustain in the future by yourself and others. Skills and tools taught here, while Python-specific, are transferable to other similar tools and programming languages.
The course is organised into the following sections:
Section 1: Software project example
In the first section, we’ll look into the software project that we will use for further testing and profiling and set up our virtual environment.
- we can obtain the project from its GitHub repository.
- the structure of the software is determined by its architecture, which also affects how the testing is done.
- to avoid conflicts between different versions of Python distributions and packages, we will create a separate virtual environment.
Section 2: Unit testing
In this section we are going to establish what is included in software testing and how we can perform the basic type of it, unit testing.
- Unit testing for testing separate functions of the software;
- how to set up a test framework and write tests to verify the behaviour of our code is correct in different situations;
- what kind of cases should we test;
- what is Test Driven Development.
Section 3: Profiling
Once we know our way around different testing tools, in this section we learn:
- how to automate and scale testing with Continuous Integration (CI) using GitHub Actions (a CI service available on GitHub).
- What is profiling
- how to use Jupyter magicks for performance time measurement
- how to use SnakeViz for resource profiling
Before We Start
A few notes before we start.
Prerequisite Knowledge
This is an intermediate-level software development course intended for people who have already been developing code in Python (or other languages) and applying it to their own problems after gaining basic software development skills. So, it is expected for you to have some prerequisite knowledge on the topics covered, as outlined at the beginning of the lesson. Check out this quiz to help you test your prior knowledge and determine if this course is for you.
Setup, Common Issues & Fixes
Have you setup and installed all the tools and accounts required for this course? Check the list of common issues, fixes & tips if you experience any problems running any of the tools you installed - your issue may be solved there.
Compulsory and Optional Exercises
Exercises are a crucial part of this course and the narrative. They are used to reinforce the points taught and give you an opportunity to practice things on your own. Please do not be tempted to skip exercises as that will get your local software project out of sync with the course and break the narrative. Exercises that are clearly marked as “optional” can be skipped without breaking things but we advise you to go through them too, if time allows. All exercises contain solutions but, wherever possible, try and work out a solution on your own.
Outdated Screenshots
Throughout this lesson we will make use and show content from Graphical User Interface (GUI) tools (Jupyter Lab and GitHub). These are evolving tools and platforms, always adding new features and new visual elements. Screenshots in the lesson may then become out-of-sync, refer to or show content that no longer exists or is different to what you see on your machine. If during the lesson you find screenshots that no longer match what you see or have a big discrepancy with what you see, please open an issue describing what you see and how it differs from the lesson content. Feel free to add as many screenshots as necessary to clarify the issue.
Let Us Know About the Issues
The original materials were adapted specifically for this workshop. They weren’t used before, and it is possible that they contain typos, code errors, or underexplained or unclear moments. Please, let us know about these issues. It will help us to improve the materials and make the next workshop better.
Key Points
For developing software that will be used by other people aside from you, it is not enough to write code that produces seemingly correct output in a few cases. You have to check that the software performs well in different conditions and with different input data, and if something goes wrong, the user is notified of this.
This lesson focuses on intermediate skills and tools for making sure that your software is correct, reliable and fast.
The lesson follows on from the novice Software Carpentry lesson, but this is not a prerequisite for attending as long as you have some basic Python, command line and Git skills and you have been using them for a while to write code to help with your work.
Section 1: Obtaining the Software Project and Preparing Virtual Environment
Overview
Teaching: 5 min
Exercises: 0 minQuestions
What tools are needed for collaborative software development?
Objectives
Provide an overview of all the different tools that will be used in this course.
The first section of the course is dedicated to setting up your environment for collaborative software development and introducing the project that we will be working on throughout the course. In order to build working (research) software efficiently and to do it in collaboration with others rather than in isolation, you will have to get comfortable with using a number of different tools interchangeably as they’ll make your life a lot easier. There are many options when it comes to deciding which software development tools to use for your daily tasks - we will use a few of them in this course that we believe make a difference. There are sometimes multiple tools for the job - we select one to use but mention alternatives too. As you get more comfortable with different tools and their alternatives, you will select the one that is right for you based on your personal preferences or based on what your collaborators are using.
Here is an overview of the tools we will be using.
Setup, Common Issues & Fixes
Have you setup and installed all the tools and accounts required for this course? Check the list of common issues, fixes & tips if you experience any problems running any of the tools you installed - your issue may be solved there.
Command Line & Python Virtual Development Environment
We will use the command line
(also known as the command line shell/prompt/console)
to run our Python code
and interact with the version control tool Git and software sharing platform GitHub.
We will also use command line tools
venv
and pip
to set up a Python virtual development environment
and isolate our software project from other Python projects we may work on.
Note: some Windows users experience the issue where Python hangs from Git Bash
(i.e. typing python causes it to just hang with no error message or output) -
see the solution to this issue.
Integrated Development Environment (IDE)
An IDE integrates a number of tools that we need to develop a software project that goes beyond a single script - including a smart code editor, a code compiler/interpreter, a debugger, etc. It will help you write well-formatted and readable code that conforms to code style guides (such as PEP8 for Python) more efficiently by giving relevant and intelligent suggestions for code completion and refactoring. IDEs often integrate command line console and version control tools - we teach them separately in this course as this knowledge can be ported to other programming languages and command line tools you may use in the future (but is applicable to the integrated versions too).
There are several popular IDEs for Python, such as IDLE, PyCharm, Spyder, VS Studio, and so on. In this course, we will use Jupyter Lab - a free, open-source IDE, widely used in the astronomic community.
Is JupyterLab actually an IDE?
JupyterLab is the next evolutionary step for the Jupyter Notebooks, a web-based interactive environment for exploratory coding. While Jupyter Notebooks lack some of the features of classical IDEs (most notably, a debugger), the latest versions of JupyterLab include all the necessary functionality. Terminology aside, JupyterLab is a very popular tool for data analysis and in the research community. More so, JupyterLab still bears a strong resemblance to Jupyter Notebooks, Google Colab and LSST Rubin Science Platform (RSP) Notebook aspect. Many astronomical platforms that provide access to computational resources and observational datasets also have Jupyter Notebooks installed. For this reason, in this course, we aim to show which tools and practices can help you write high-quality, reusable, and reliable software using JupyterLab. The original version of this course was developed for PyCharm IDE, which is usually considered to be more suited for software development that is not related to data exploration and analysis. That course is included in the Carpentries Incubator program, and you can access it here.
Git & GitHub
Git is a free and open source distributed version control system designed to save every change made to a (software) project, allowing others to collaborate and contribute. In this course, we use Git to version control our code in conjunction with GitHub for code backup and sharing. GitHub is one of the leading integrated products and social platforms for modern software development, monitoring and management - it will help us with version control, issue management, code review, code testing/Continuous Integration, and collaborative development. An important concept in collaborative development is version control workflows (i.e. how to effectively use version control on a project with others).
Python Coding Style
Most programming languages will have associated standards and conventions for how the source code should be formatted and styled. Although this sounds pedantic, it is important for maintaining the consistency and readability of code across a project. Therefore, one should be aware of these guidelines and adhere to whatever the project you are working on has specified. In Python, we will be looking at a convention called PEP8.
Let’s get started with setting up our software development environment!
Key Points
In order to develop (write, test, debug, backup) code efficiently, you need to use a number of different tools.
When there is a choice of tools for a task you will have to decide which tool is right for you, which may be a matter of personal preference or what the team or community you belong to is using.
A popular tool for organizing collaborative software development is Git, that allows you to share your code with other people and keep track of its changes.
Introduction to Our Software Project
Overview
Teaching: 15 min
Exercises: 10 minQuestions
How to obtain software project we will be working on?
What is the structure of our software project?
Objectives
Use Git to obtain a working copy of our software project from GitHub.
Inspect the structure and architecture of our software project.
Light Curve Analysis Project
For this workshop, let’s assume that you have joined a software development team that has been working on the light curve analysis project developed in Python and stored on GitHub. The purpose of this software is to analyze the variability of astronomical sources, using observations that come from different instruments.

What Does Light Curve Dataset Contain?
For developing and testing our software project, we will use two RR Lyrae candidates variability datasets.
The first dataset,
kepler_RRLyr.csv, contains observations coming from the Kepler space telescope. In this dataset, all observations are related to the same source, i.e. the whole table represents a single light curve. The second dataset,lsst_RRLyr.pkl, contains synthetic observations of 25 presumably variable sources from the LSST Data Preview 0. Considering that the datasets come from different instruments, they also have different formats and column names - a common situation in real life. It is always a good idea to develop your software in such a way that it remains usable even if the format of the input data has changed. We will use the differences of the datasets to illustrate some of the topics during this workshop.
The project is not finished and contains some errors. You will be working on your own and in collaboration with others to fix and build on top of the existing code during the course.
Downloading Our Software Project
To start working on the project, you will first create a copy of the software project template repository from GitHub within your own GitHub account and then obtain a local copy of that project (from your GitHub) on your machine.
- Make sure you have a GitHub account and that you have set up your SSH key pair for authentication with GitHub, as explained in Setup.
- Log into your GitHub account.
-
Go to the software project repository in GitHub.

-
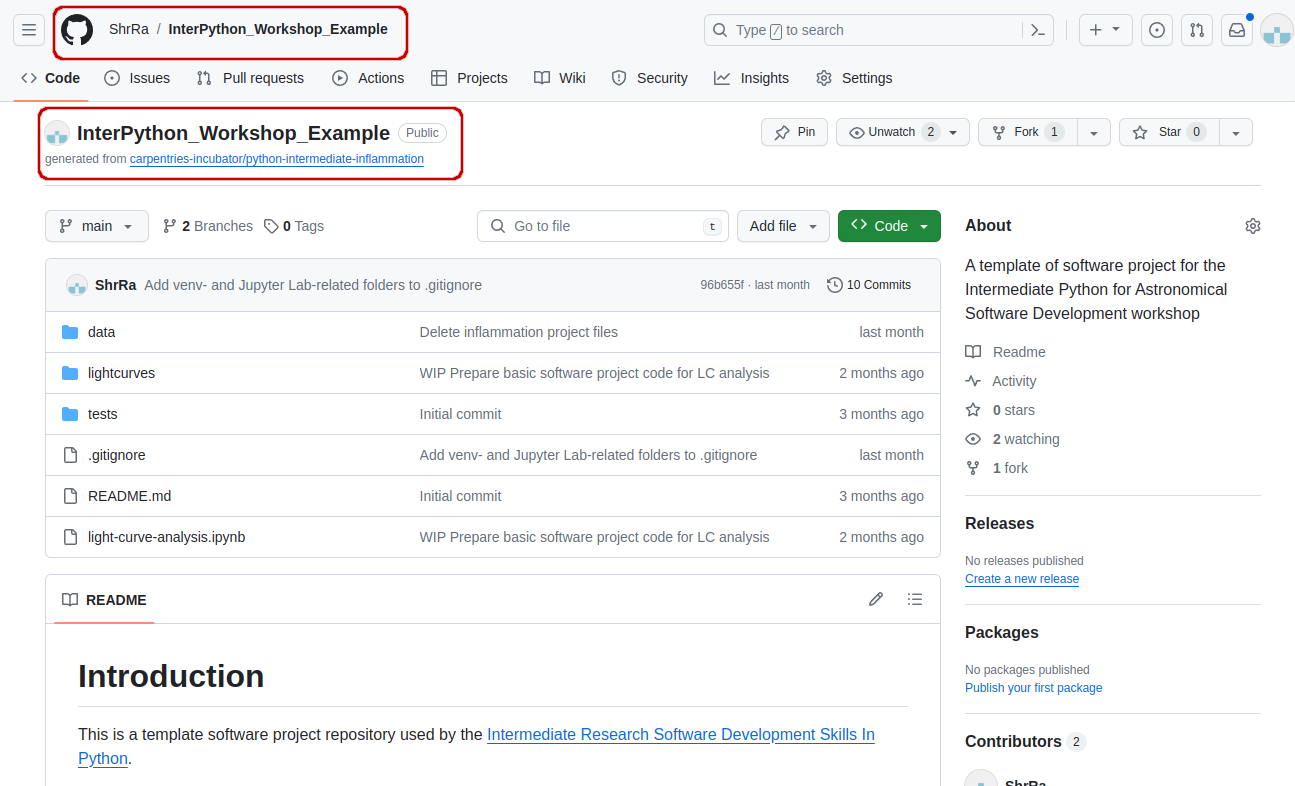
Click the
Forkbutton towards the top right of the repository’s GitHub page to create a fork of the repository under your GitHub account. Remember, you will need to be signed into GitHub for theForkbutton to work.Note: each participant is creating their own fork of the project to work on.
-
Make sure to select your personal account and set the name of the project to
InterPython_Workshop_Example(you can call it anything you like, but it may be easier for future group exercises if everyone uses the same name). For this workshop, set the new repository’s visibility to ‘Public’ - In this case, it can be seen by others. Select theCopy the main branch onlycheckbox, since you will be creating additional branches by yourself.
- Click the
Create forkbutton and wait for GitHub to import the copy of the repository under your account. -
Locate the forked repository under your own GitHub account. GitHub should redirect you there automatically after creating the fork. If this does not happen, click your user icon in the top right corner and select Your Repositories from the drop-down menu, then locate your newly created fork.
Exercise: Obtain the Software Project Locally
Using the command line, clone the copied repository from your GitHub account into the home directory on your computer using SSH. Which command(s) would you use to get a detailed list of contents of the directory you have just cloned?
Solution
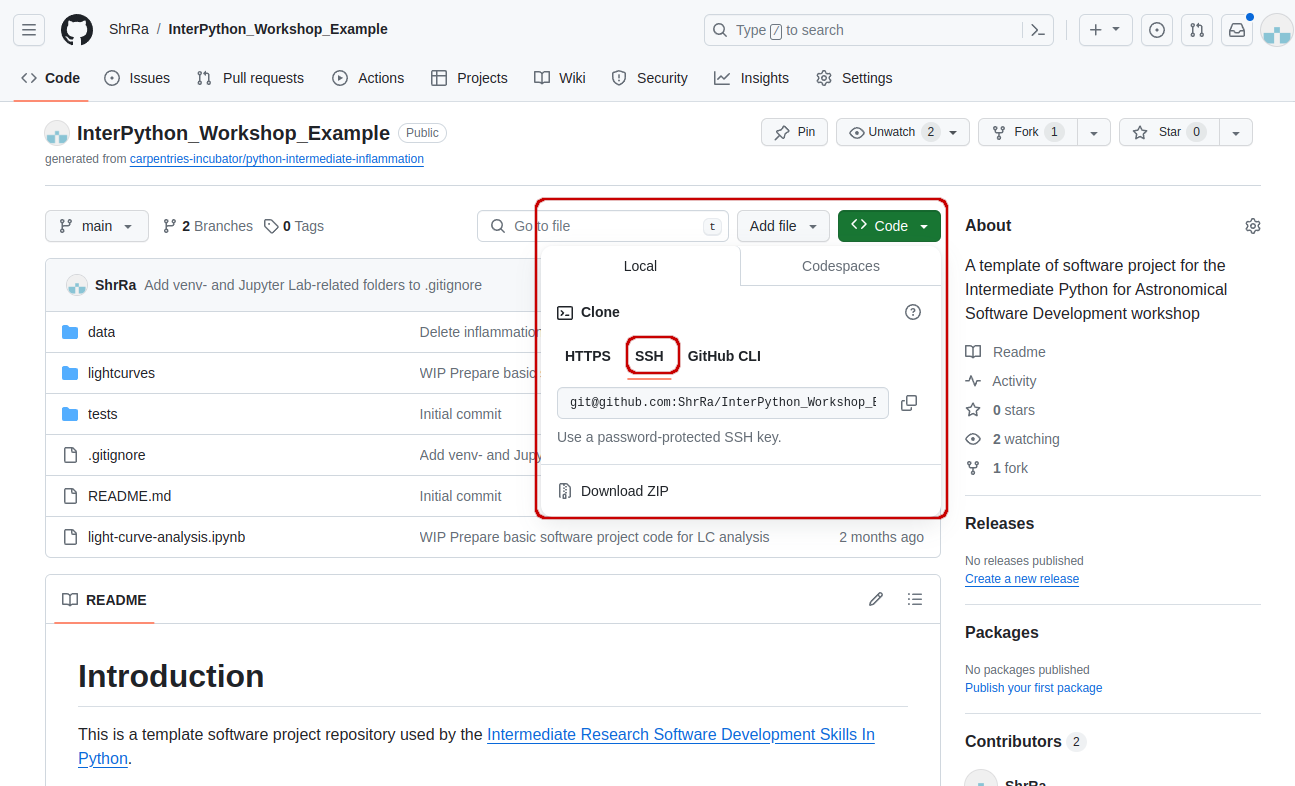
- Find the SSH URL of the software project repository to clone from your GitHub account. Make sure you do not clone the original template repository but rather your own copy, as you should be able to push commits to it later on. Also make sure you select the SSH tab and not the HTTPS one. These two protocols implement different security measures, and since 2021 GitHub offers full support only for the SSH cloning; namely, you won’t be able to send your changes to the repository if you use HTTPS method.
- Make sure you are located in your home directory in the command line with:
$ cd ~- From your home directory in the command line, do:
$ git clone git@github.com:<YOUR_GITHUB_USERNAME>/InterPython_Workshop_Example.gitMake sure you are cloning your copy of the software project and not the template repository.
- Navigate into the cloned repository folder in your command line with:
$ cd InterPython_Workshop_ExampleNote: If you have accidentally copied the HTTPS URL of your repository instead of the SSH one, you can easily fix that from your project folder in the command line with:
$ git remote set-url origin git@github.com:<YOUR_GITHUB_USERNAME>/InterPython_Workshop_Example.git
Our Software Project Structure
Let’s inspect the content of the software project from the command line.
From the root directory of the project,
you can use the command ls -l to get a more detailed list of the contents.
You should see something similar to the following.
$ cd ~/InterPython_Workshop_Example
$ ls -l
total 284
drwxrwxr-x 2 alex alex 52 Jan 10 20:29 data
-rw-rw-r-- 1 alex alex 285218 Jan 10 20:29 light-curve-analysis.ipynb
drwxrwxr-x 2 alex alex 58 Jan 10 20:29 lcanalyzer
-rw-rw-r-- 1 alex alex 1171 Jan 10 20:29 README.md
drwxrwxr-x 2 alex alex 51 Jan 10 20:29 tests
...
As can be seen from the above, our software project contains the README file
(that typically describes the project, its usage, installation, authors and how to contribute),
Jupyter Notebook light-curve-analysis.ipynb, and three directories - lcanalyzer, data and tests.
The Jupyter Notebook light-curve-analysis.ipynb is where exploratory analysis is done,
and on closer inspection, we can see that the lcanalyzer directory contains two Python
scripts - views.py and models.py. We will have a more detailed look into these shortly.
$ cd ~/InterPython_Workshop_Example/lcanalyzer
$ ls -l
total 12
-rw-rw-r-- 1 alex alex 903 Jan 10 20:29 models.py
-rw-rw-r-- 1 alex alex 718 Jan 10 20:29 views.py
...
Directory data contains three files with the lightcurves coming from two instruments, Kepler and LSST:
$ cd ~/InterPython_Workshop_Example/data
$ ls -l
total 24008
-rw-rw-r-- 1 alex alex 23686283 Jan 10 20:29 kepler_RRLyr.csv
-rw-rw-r-- 1 alex alex 895553 Jan 10 20:29 lsst_RRLyr.pkl
-rw-rw-r-- 1 alex alex 895553 Jan 10 20:29 lsst_RRLyr_protocol_4.pkl
...
The lsst_RRLyr_protocol_4.pkl file contains the same data as lsst_RRLyr.pkl, but it’s saved
using an older data protocol, compatible with older versions of the packages we’ll be using.
Exercise: Have a Peek at the Data
Which command(s) would you use to list the contents or a first few lines of
data/kepler_RRLyr.csvfile?Solution
- To list the entire content of a file from the project root do:
cat data/kepler_RRLyr.csv.- To list the first 5 lines of a file from the project root do:
head -n 5 data/kepler_RRLyr.csv.time,flux,flux_err,quality,timecorr,centroid_col,centroid_row,cadenceno,sap_flux,sap_flux_err,sap_bkg,sap_bkg_err,pdcsap_flux,pdcsap_flux_err,sap_quality,psf_centr1,psf_centr1_err,psf_centr2,psf_centr2_err,mom_centr1,mom_centr1_err,mom_centr2,mom_centr2_err,pos_corr1,pos_corr2 ...Pay attention that while the
.csvformat is human-readable, if you try to runhead -n 5 data/lsst_RRLyr.pkl, the output will be non-human-readable.
Directory tests contains several tests that have been implemented already.
We will be adding more tests during the course as our code grows.
$ ls -l tests
total 8
-rw-rw-r-- 1 alex alex 941 Jan 10 20:29 test_models.py
...
An important thing to note here is that the structure of the project is not arbitrary. One of the big differences between novice and intermediate software development is planning the structure of your code. This structure includes software components and behavioural interactions between them (including how these components are laid out in a directory and file structure). A novice will often make up the structure of their code as they go along. However, for more advanced software development, we need to plan this structure - called a software architecture - beforehand.
Let’s have a more detailed look into what a software architecture is and which architecture is used by our software project before we start adding more code to it.
Software Architecture
A software architecture is the fundamental structure of a software system that is decided at the beginning of project development based on its requirements and cannot be changed that easily once implemented. It refers to a “bigger picture” of a software system that describes high-level components (modules) of the system and how they interact.
In software design and development,
large systems or programs are often decomposed into a set of smaller modules
each with a subset of functionality.
Typical examples of modules in programming are software libraries;
some software libraries, such as numpy and matplotlib in Python,
are bigger modules that contain several smaller sub-modules.
Another example of modules are classes in object-oriented programming languages.
Model-View-Controller (MVC) Architecture
For our project, we are using Model-View-Controller (MVC) Architecture. MVC architecture divides the related program logic into three interconnected modules:
- Model (data)
- View (client interface), and
- Controller (processes that handle input/output and manipulate the data).
Model represents the data used by a program and also contains operations/rules for manipulating and changing the data in the model. This may be a database, a file, a single data object or a series of objects - for example, a table representing light curve observations.
View is the means of displaying data to users/clients within an application (i.e., by providing visualisation of the state of the model). For example, displaying a window with input fields and buttons (Graphical User Interface, GUI), textual options within a command line (Command Line Interface, CLI) or plots are examples of Views. They include anything that the user can see from the application.
Controller manipulates both the Model and the View. It accepts input from the View and performs the corresponding action on the Model (changing the state of the model) and then updates the View accordingly. For example, on user request, Controller updates a picture on a user’s GitHub profile and then modifies the View by displaying the updated profile back to the user.
Separation of Concerns
Separation of concerns is important when designing software architectures in order to reduce the code’s complexity. Note, however, there are limits to everything - and MVC architecture is no exception. Controller often transcends into Model and View and a clear separation is sometimes difficult to maintain. For example, the Command Line Interface provides both the View (what user sees and how they interact with the command line) and the Controller (invoking of a command) aspects of a CLI application. In Web applications, Controller often manipulates the data (received from the Model) before displaying it to the user or passing it from the user to the Model.
Our Project’s MVC Architecture
In our case, the file light-curve-analysis.ipynb is the Controller module
that performs basic statistical analysis over light curve data
and provides the main entry point of the code.
The View and Model modules are contained in the files views.py and models.py, respectively,
and are conveniently named.
Data underlying the Model is contained within the directory data -
as we have seen already it contains several files with light curves.
Further reading
If you want to learn more about software architecture and MVC topics, you can look into the corresponding episodes of the previous InterPython workshops: software’s requirements and software design.
We now proceed to set up our virtual development environment and start working with the code using an IDE Jupyter Lab.
Key Points
Using Git and Github, we can share our code with others and obtain our own copies of others’ projects.
The structure of the software project is defined by its purposes and requirements.
Separation of concerns is one of the most basic principles when deciding on software architecture.
Virtual Environments For Software Development
Overview
Teaching: 20 min
Exercises: 0 minQuestions
What are virtual environments in software development and why you should use them?
How can we manage Python virtual environments and external (third-party) libraries?
What IDEs can we use for more convenient code development?
Objectives
Set up a Python virtual environment for our software project using
venvandpip.Run our software from the command line.
Obtain Jupyter Lab IDE.
Introduction
So far we have cloned our software project from GitHub and inspected its contents and architecture a bit. We now want to run our code to see what it does - let’s do that from the command line. For the most part of the course we will develop the code using an IDE Jupyter Lab, and interact with Git from the command line. While it is possible to use Git with a Jupyter Lab extension (and many other IDEs have built-in functionality for this too), typing commands in the command line allows you to familiarise yourself and learn it well. Running Git from the command line does not depend on the IDE and for the most part, uses the same commands in different OS, so it is the most universal way of using it.
If you have a little peek into our code
(e.g. run cat lcanalyzer/views.py from the project root),
you will see the following two lines somewhere at the top.
from matplotlib import pyplot as plt
import pandas as pd
This means that our code requires two external libraries
(also called third-party packages or dependencies) -
pandas and matplotlib.
Python applications often use external libraries that don’t come as part of the standard Python distribution.
This means that you will have to use a package manager tool to install them on your system.
Applications will also sometimes need a
specific version of an external library
(e.g. because they were written to work with feature, class,
or function that may have been updated in more recent versions),
or a specific version of Python interpreter.
This means that each Python application you work with may require a different setup
and a set of dependencies so it is useful to be able to keep these configurations
separate to avoid confusion between projects.
The solution to this problem is to create a self-contained
virtual environment per project,
which contains a particular version of Python installation
plus a number of additional external libraries.
Virtual environments are not just a feature of Python - most modern programming languages use them to isolate libraries for a specific project and make it easier to develop, run, test and share code with others. Even languages that don’t explicitly have virtual environments have other mechanisms that promote per-project library collections. In this episode, we learn how to set up a virtual environment to develop our code and manage our external dependencies.
Virtual Environments
A Python virtual environment helps us create an isolated working copy of a software project that uses a specific version of Python interpreter together with specific versions of external libraries. Python virtual environments are implemented as directories with a particular structure within software projects, containing links to specified dependencies allowing isolation from other software projects on your machine that may require different versions of Python or external libraries.
As more external libraries are added to your Python project over time, you can add them to its specific virtual environment and avoid a great deal of confusion by having separate (smaller) virtual environments for each project rather than one huge global environment with potential package version clashes. Another big motivator for using virtual environments is that they make sharing your code with others much easier (as we will see shortly). Here are some typical scenarios where the use of virtual environments is highly recommended (almost unavoidable):
- You have an older project that only works under Python 2. You do not have the time to migrate the project to Python 3 or it may not even be possible as some of the third party dependencies are not available under Python 3. You have to start another project under Python 3. The best way to do this on a single machine is to set up two separate Python virtual environments.
- One of your Python 3 projects is locked to use a particular older version of a third party dependency. You cannot use the latest version of the dependency as it breaks things in your project. In a separate branch of your project, you want to try and fix problems introduced by the new version of the dependency without affecting the working version of your project. You need to set up a separate virtual environment for your branch to ‘isolate’ your code while testing the new feature.
- You often work on the code developed by others. Everyone will have their own set of libraries installed, and some developers may have different versions of the same library. Trying to run someone’s code with the wrong version of a library will cause issues.
You do not have to worry too much about specific versions of external libraries that your project depends on most of the time. Virtual environments also enable you to always use the latest available version without specifying it explicitly. They also enable you to use a specific older version of a package for your project, should you need to.
A Specific Python or Package Version is Only Ever Installed Once
Note that you will not have separate Python or package installations for each of your projects - they will only ever be installed once on your system but will be referenced from different virtual environments.
Managing Python Virtual Environments
There are several commonly used command line tools for managing Python virtual environments:
venv, available by default from the standardPythondistribution fromPython 3.3+virtualenv, needs to be installed separately but supports bothPython 2.7+andPython 3.3+versionspipenv, created to fix certain shortcomings ofvirtualenvconda, package and environment management system (also included as part of the Anaconda Python distribution often used by the scientific community)poetry, a modern Python packaging tool which handles virtual environments automatically
While there are pros and cons for using each of the above,
all will do the job of managing Python virtual environments for you
and it may be a matter of personal preference which one you go for.
In this course, we will use venv to create and manage our virtual environment
(which is the default virtual environment manager for Python 3.3+).
Managing External Packages
Part of managing your (virtual) working environment involves
installing, updating and removing external packages on your system.
The Python package manager tool pip is most commonly used for this -
it interacts and obtains the packages from the central repository called
Python Package Index (PyPI).
pip can now be used with all Python distributions (including Anaconda).
A Note on Anaconda and
condaAnaconda is an open source Python distribution commonly used for scientific programming - it conveniently installs Python, package and environment management
conda, and a number of commonly used scientific computing packages so you do not have to obtain them separately.condais an independent command line tool (available separately from the Anaconda distribution too) with dual functionality: (1) it is a package manager that helps you find Python packages from remote package repositories and install them on your system, and (2) it is also a virtual environment manager. So, you can usecondafor both tasks instead of usingvenvandpip. However, there are some differences in the waypipandcondawork. Quoting Jake VanderPlas, “pipinstalls python packages in any environment.condainstalls any package incondaenvironments. If your project is purely Python,venvis a cleaner and more lightweight tool.condais more convenient if you need to install non-Python packages. Here is more in-depth analysis of the topic.Another case when
condais more convenient is when you need to create many environments with different versions of Python. Instead of installing the needed Python version manually, withcondayou can do it with a one-liner:$ conda create -n envname python=*.**If you have
condainstalled on your PC, make sure to deactivatecondaenvironments before usingvenv$ conda deactivateWhile you can, in principle, have both
condaandvenvvirtual environments activated, you should avoid this situation as it is likely to produce issues. The names of the active environments are listed in parenthesis before your current location path, so if there are two environments listed, deactivate one of them.(conda_base) (venv) alex@Serenity:/mnt/Data/Work/GitHub/InterPython_Workshop_Example$
Many Tools for the Job
Installing and managing Python distributions,
external libraries and virtual environments is, well, complex.
There is an abundance of tools for each task,
each with its advantages and disadvantages,
and there are different ways to achieve the same effect
(and even different ways to install the same tool!).
Note that each Python distribution comes with its own version of pip -
and if you have several Python versions installed you have to be extra careful to
use the correct pip to manage external packages for that Python version.
venv and pip are considered the de facto standards for virtual environment
and package management for Python 3.
However, the advantages of using Anaconda and conda are that
you get (most of the) packages needed for scientific code development included with the distribution.
If you are only collaborating with others who are also using Anaconda,
you may find that conda satisfies all your needs.
As you become more familiar with different tools you will realise that they work in a similar way even though the command syntax may be different (and that there are equivalent tools for other programming languages too to which your knowledge can be ported).
Python Environment Hell
From XKCD (Creative Commons Attribution-NonCommercial 2.5 License)
Let us have a look at how we can create and manage virtual environments from the command line
using venv and manage packages using pip.
Creating Virtual Environments Using venv
Creating a virtual environment with venv is done by executing the following command:
$ python3 -m venv /path/to/new/virtual/environment
where /path/to/new/virtual/environment is a path to a directory where you want to place it -
conventionally within your software project so they are co-located.
This will create the target directory for the virtual environment
(and any parent directories that don’t exist already).
For our project let’s create a virtual environment called “venv”. First, ensure you are within the project root directory, then:
$ python3 -m venv venv
If you list the contents of the newly created directory “venv”, on a Mac or Linux system (slightly different on Windows as explained below) you should see something like:
$ ls -l venv
total 8
drwxr-xr-x 12 alex staff 384 5 Oct 11:47 bin
drwxr-xr-x 2 alex staff 64 5 Oct 11:47 include
drwxr-xr-x 3 alex staff 96 5 Oct 11:47 lib
-rw-r--r-- 1 alex staff 90 5 Oct 11:47 pyvenv.cfg
So, running the python3 -m venv venv command created the target directory called “venv”
containing:
pyvenv.cfgconfiguration file with a home key pointing to the Python installation from which the command was run,binsubdirectory (calledScriptson Windows) containing a symlink of the Python interpreter binary used to create the environment and the standard Python library,lib/pythonX.Y/site-packagessubdirectory (calledLib\site-packageson Windows) to contain its own independent set of installed Python packages isolated from other projects,- various other configuration and supporting files and subdirectories.
Naming Virtual Environments
What is a good name to use for a virtual environment? Using “venv” or “.venv” as the name for an environment and storing it within the project’s directory seems to be the recommended way - this way when you come across such a subdirectory within a software project, by convention you know it contains its virtual environment details. A slight downside is that all different virtual environments on your machine then use the same name and the current one is determined by the context of the path you are currently located in. A (non-conventional) alternative is to use your project name for the name of the virtual environment, with the downside that there is nothing to indicate that such a directory contains a virtual environment. In our case, we have settled to use the name “venv” instead of “.venv” since it is not a hidden directory and we want it to be displayed by the command line when listing directory contents (the “.” in its name that would, by convention, make it hidden). In the future, you will decide what naming convention works best for you. Here are some references for each of the naming conventions:
- The Hitchhiker’s Guide to Python notes that “venv” is the general convention used globally
- The Python Documentation indicates that “.venv” is common
- “venv” vs “.venv” discussion
Once you’ve created a virtual environment, you will need to activate it.
On Mac or Linux, it is done as:
$ source venv/bin/activate
(venv) $
On Windows, recall that we have Scripts directory instead of bin
and activating a virtual environment is done as:
$ source venv/Scripts/activate
(venv) $
Activating the virtual environment will change your command line’s prompt to show what virtual environment you are currently using (indicated by its name in round brackets at the start of the prompt), and modify the environment so that running Python will get you the particular version of Python configured in your virtual environment.
You can verify you are using your virtual environment’s version of Python
by checking the path using the command which:
(venv) $ which python3
/home/alex/InterPython_Workshop_Example/venv/bin/python3
When you’re done working on your project, you can exit the environment with:
(venv) $ deactivate
If you’ve just done the deactivate,
ensure you reactivate the environment ready for the next part:
$ source venv/bin/activate
(venv) $
Python Within A Virtual Environment
Within a virtual environment, commands
pythonandpipwill refer to the version of Python you created the environment with. If you create a virtual environment withpython3 -m venv venv,pythonwill refer topython3andpipwill refer topip3.On some machines with Python 2 installed,
pythoncommand may refer to the copy of Python 2 installed outside of the virtual environment instead, which can cause confusion. You can always check which version of Python you are using in your virtual environment with the commandwhich pythonto be absolutely sure. We continue usingpython3andpip3in this material to avoid confusion for those users, but commandspythonandpipmay work for you as expected.
Note that, since our software project is being tracked by Git, the newly created virtual environment will show up in version control - we will see how to handle it using Git in one of the subsequent episodes.
Installing External Packages Using pip
We noticed earlier that our code depends on two external packages/libraries -
pandas and matplotlib.
In order for the code to run on your machine,
you need to install these two dependencies into your virtual environment.
To install the latest version of a package with pip
you use pip’s install command and specify the package’s name, e.g.:
(venv) $ pip3 install pandas
(venv) $ pip3 install matplotlib
or like this to install multiple packages at once for short:
(venv) $ pip3 install pandas matplotlib
How About
python3 -m pip install?Why are we not using
pipas an argument topython3command, in the same way we did withvenv(i.e.python3 -m venv)?python3 -m pip installshould be used according to the official Pip documentation; other official documentation still seems to have a mixture of usages. Core Python developer Brett Cannon offers a more detailed explanation of edge cases when the two options may produce different results and recommendspython3 -m pip install. We kept the old-style command (pip3 install) as it seems more prevalent among developers at the moment - but it may be a convention that will soon change and certainly something you should consider.
If you run the pip3 install command on a package that is already installed,
pip will notice this and do nothing.
To install a specific version of a Python package
give the package name followed by == and the version number,
e.g. pip3 install pandas==2.1.2.
To specify a minimum version of a Python package,
you can do pip3 install pandas>=2.1.0.
To upgrade a package to the latest version, e.g. pip3 install --upgrade pandas.
To display information about a particular installed package do:
(venv) $ pip3 show pandas
Name: pandas
Version: 2.1.4
Summary: Powerful data structures for data analysis, time series, and statistics
Home-page: https://pandas.pydata.org
Author:
Author-email: The Pandas Development Team <pandas-dev@python.org>
License: BSD 3-Clause License
...
Requires: numpy, python-dateutil, pytz, tzdata
Required-by:
To list all packages installed with pip (in your current virtual environment):
(venv) $ pip3 list
Package Version
--------------- -------
contourpy 1.2.0
cycler 0.12.1
fonttools 4.47.2
kiwisolver 1.4.5
matplotlib 3.8.2
numpy 1.26.3
packaging 23.2
pandas 2.1.4
pillow 10.2.0
pip 23.3.2
pyparsing 3.1.1
python-dateutil 2.8.2
pytz 2023.3.post1
setuptools 65.5.0
six 1.16.0
tzdata 2023.4
To uninstall a package installed in the virtual environment do: pip3 uninstall package-name.
You can also supply a list of packages to uninstall at the same time.
Exporting/Importing Virtual Environments Using pip
You are collaborating on a project with a team so, naturally,
you will want to share your environment with your collaborators
so they can easily ‘clone’ your software project with all of its dependencies
and everyone can replicate equivalent virtual environments on their machines.
pip has a handy way of exporting, saving and sharing virtual environments.
To export your active environment -
use pip3 freeze command to produce a list of packages installed in the virtual environment.
A common convention is to put this list in a requirements.txt file:
(venv) $ pip3 freeze > requirements.txt
(venv) $ cat requirements.txt
contourpy==1.2.0
cycler==0.12.1
fonttools==4.47.2
kiwisolver==1.4.5
matplotlib==3.8.2
numpy==1.26.3
packaging==23.2
pandas==2.1.4
pillow==10.2.0
pyparsing==3.1.1
python-dateutil==2.8.2
pytz==2023.3.post1
six==1.16.0
tzdata==2023.4
The first of the above commands will create a requirements.txt file in your current directory.
Yours may look a little different,
depending on the version of the packages you have installed,
as well as any differences in the packages that they themselves use.
The requirements.txt file can then be committed to a version control system
(we will see how to do this using Git in one of the following episodes)
and get shipped as part of your software and shared with collaborators and/or users.
They can then replicate your environment
and install all the necessary packages from the project root as follows:
(venv) $ pip3 install -r requirements.txt
As your project grows - you may need to update your environment for a variety of reasons.
For example, one of your project’s dependencies has just released a new version
(dependency version number update),
you need an additional package for data analysis (adding a new dependency)
or you have found a better package and no longer need the older package
(adding a new and removing an old dependency).
What you need to do in this case
(apart from installing the new and removing the packages that are no longer needed
from your virtual environment)
is update the contents of the requirements.txt file accordingly
by re-issuing pip freeze command
and propagate the updated requirements.txt file to your collaborators
via your code sharing platform (e.g. GitHub).
Official Documentation
For a full list of options and commands, consult the official
venvdocumentation and the Installing Python Modules withpipguide. Also check out the guide “Installing packages usingpipand virtual environments”.
Installing Jupyter Lab
Jupyter Lab itself comes as a Python package. Therefore, we have to install it
in the environment as well. Another package that we will need for our project is astropy,
which provides a lot of functions, useful for writing astronomical software and data processing.
(venv) $ pip3 install astropy
(venv) $ pip3 install jupyterlab
Do not forget to update the requirements.txt file after the installation is finished.
If you run pip freeze, you will see that Jupyter Lab installed a lot of dependencies libraries,
so the list of requirements is now much larger.
Key Points
Virtual environments keep Python versions and dependencies required by different projects separate.
A virtual environment is itself a directory structure.
Use
venvto create and manage Python virtual environments.Use
pipto install and manage Python external (third-party) libraries.
pipallows you to declare all dependencies for a project in a separate file (by convention calledrequirements.txt) which can be shared with collaborators/users and used to replicate a virtual environment.Use
pip3 freeze > requirements.txtto take snapshot of your project’s dependencies.Use
pip3 install -r requirements.txtto replicate someone else’s virtual environment on your machine from therequirements.txtfile.
Section 2: Ensuring Correctness of Software at Scale
Overview
Teaching: 5 min
Exercises: 0 minQuestions
What should we do to ensure our code is correct?
Objectives
Introduce the testing tools, techniques, and infrastructure that will be used in this section.
We’ve just set up a suitable environment for the development of our software project and are ready to start developing new features. However, we want to make sure that the new code we contribute to the project is actually correct and is not breaking any of the existing code. So, in this section, we’ll look at testing approaches that can help us ensure that the software we write is behaving as intended, and how we can diagnose and fix issues once faults are found. Using such approaches requires us to change our practice of development. This can take time, but potentially saves us considerable time in the medium to long term by allowing us to more comprehensively and rapidly find such faults, as well as giving us greater confidence in the correctness of our code - so we should try and employ such practices early on. We will also make use of techniques and infrastructure that allow us to do this in a scalable, automated and more performant way as our codebase grows.
In this section we will:
- Make use of a test framework called Pytest, a free and open source Python library to help us structure and run automated tests.
- Design, write and run unit tests using Pytest to verify the correct behaviour of code and identify faults, making use of test parameterisation to increase the number of different test cases we can run.
- Try out Test-Driven Development, an work approach based on developing the checks before writing the code itself.
Key Points
Using testing requires us to change our practice of code development, but saves time in the long run by allowing us to more comprehensively and rapidly find faults in code, as well as giving us greater confidence in the correctness of our code.
Writing parametrized tests makes sure that you are testing your software in different scenarios.
Writing tests before the features forces you to think of the requirements and best possible implementations in advance.
Automatically Testing Software
Overview
Teaching: 25 min
Exercises: 15 minQuestions
Does the code we develop work the way it should do?
Can we (and others) verify these assertions for themselves?
To what extent are we confident of the accuracy of results that appear in publications?
Objectives
Explain the reasons why testing is important
Describe the three main types of tests and what each are used for
Implement and run unit tests to verify the correct behaviour of program functions
Introduction
Being able to demonstrate that a process generates the right results is important in any field of research, whether it’s software generating those results or not. So when writing software we need to ask ourselves some key questions:
- Does the code we develop work the way it should do?
- Can we (and others) verify these assertions for themselves?
- Perhaps most importantly, to what extent are we confident of the accuracy of results that software produces?
If we are unable to demonstrate that our software fulfills these criteria, why would anyone use it? Having well-defined tests for our software is useful for this, but manually testing software can prove an expensive process.
Automation can help, and automation where possible is a good thing - it enables us to define a potentially complex process in a repeatable way that is far less prone to error than manual approaches. Once defined, automation can also save us a lot of effort, particularly in the long run. In this episode we’ll look into techniques of automated testing to improve the predictability of a software change, make development more productive, and help us produce code that works as expected and produces desired results.
What Is Software Testing?
For the sake of argument, if each line we write has a 99% chance of being right, then a 70-line program will be wrong more than half the time. We need to do better than that, which means we need to test our software to catch these mistakes.
We can and should extensively test our software manually, and manual testing is well-suited to testing aspects such as graphical user interfaces and reconciling visual outputs against inputs. However, even with a good test plan, manual testing is very time consuming and prone to error. Another style of testing is automated testing, where we write code that tests the functions of our software. Since computers are very good and efficient at automating repetitive tasks, we should take advantage of this wherever possible.
There are three main types of automated tests:
- Unit tests are tests for fairly small and specific units of functionality, e.g. determining that a particular function returns output as expected given specific inputs.
- Functional or integration tests work at a higher level, and test functional paths through your code, e.g. given some specific inputs, a set of interconnected functions across a number of modules (or the entire code) produce the expected result. These are particularly useful for exposing faults in how functional units interact.
- Regression tests make sure that your program’s output hasn’t changed, for example after making changes your code to add new functionality or fix a bug.
For the purposes of this course, we’ll focus on unit tests. But the principles and practices we’ll talk about can be built on and applied to the other types of tests too.
Set Up a New Feature Branch for Writing Tests
We’re going to look at how to run some existing tests and also write some new ones,
so let’s ensure we’re initially on our develop branch we created earlier.
And then, we’ll create a new feature branch called test-suite off the develop branch -
a common term we use to refer to sets of tests - that we’ll use for our test writing work:
$ git checkout develop
$ git branch test-suite
$ git checkout test-suite
Good practice is to write our tests around the same time we write our code on a feature branch. But since the code already exists, we’re creating a feature branch for just these extra tests. Git branches are designed to be lightweight, and where necessary, transient, and use of branches for even small bits of work is encouraged.
Later on, once we’ve finished writing these tests and are convinced they work properly,
we’ll merge our test-suite branch back into develop.
Don’t forget to activate our venv environment, launch Jupyter Notebook and let’s see
how we can test our software for light curve analysis.
Using Jupyter Lab
Let’s open our project in Jupyter Lab.
Jupyter Lab interface
To launch Jupyter Lab, activate the venv environment created in the previous episode and type in the terminal:
(venv) $ jupyter lab
The output will look similar to this:
To access the server, open this file in a browser:
file:///home/alex/.local/share/jupyter/runtime/jpserver-2946113-open.html
Or copy and paste one of these URLs:
http://localhost:8888/lab?token=e2aff7125e9917868a16b8b627f73995eb83effbcafeee05
http://127.0.0.1:8888/lab?token=e2aff7125e9917868a16b8b627f73995eb83effbcafeee05
Now you can click on one of the URLs below and Jupyter Lab will open in your browser.
Lightcurve Data Analysis
Let’s go back to our lightcurve analysis software project.
Recall that it contains a data directory, where we have observations of presumably variable stars, namely RR Lyrae candidates, coming
from two sources: the Kepler Space Telescope and LSST Data Preview 0.
Let’s open our data and have a look at it. For this we will use pandas package.
Import it, open the lsst_RRLyr.pkl catalogue and have a look at the format of this table.
Don’t forget to put your code in the sections where it belongs!
import pandas as pd
lc_datasets = {}
lc_datasets['lsst'] = pd.read_pickle('data/lsst_RRLyr.pkl')
lc_datasets['lsst'].info()
lc_datasets['lsst'].head()
We can see that the dataset contains 11177 rows (‘entries’) and 12 columns.
the lc_datasets['lsst'].info() function also informs us about the types of the data in the columns,
as well as about the number of non-null values in each column.
Having a look at the top 5 rows (lc_datasets['lsst'].head()) gives us an impression of what kind
of values we have in each column.
For now there are four columns that we’ll need:
- ‘objectId’ that contains identificators of the observed objects;
- ‘band’ that informs us about the band in which the observation is made;
- ‘expMidptMJD’ that contains the time stamp of the observation;
- ‘psfMag’ that containes measured magnitudes.
Let’s assume that we want to know the maximum measured magnitudes of
the light curves in each band for a single
object. Our dataset contains observations in all bands for a number of sources, so we have
to a) pick only one source, and b) separate the observations in different bands from each other.
There are many ways of how to do this, but for the purposes of this episode we
will store the single-source observational data for each band in a dictionary
and then apply the max_mag function defined in our models.py file.
First, pick an id of the object that we will investigate.
### Pick an object
obj_id = lc_datasets['lsst']['objectId'].unique()[4]
And then store its observations in each band as items of a dictionary
lc.
### Get all the observations for this obj_id for each band
# Create an empty dict
lc = {}
# Define the bands names
bands = 'ugrizy'
# For each band create a bool array that indicates
# that this observation belongs to a certain object and is made in a
# certain band
for b in bands:
filt_band_obj = (lc_datasets['lsst']['objectId'] == obj_id) & (
lc_datasets['lsst']['band'] == b
)
# Select the observations and store in the dict 'lc'
lc[b] = lc_datasets['lsst'][filt_band_obj]
Have a look at the resulting dictionary: you will find that each element has a key corresponding to the band name, and it’s value will contain a Pandas DataFrame with observations in this band.
Now we need to import the functions from the models.py file.
We should do it in the ‘Imports’ section.
import lcanalyzer.models as models
Pick a function from this module, for example, max_mag, and apply it to one of the light
curves.
models.max_mag(lc['g'],'psfMag')
19.183367224358136
How would you check if our max_mag function works correctly?
Don’t forget about the best practices
There are some best practices recommended when working with Jupyter Notebooks, and one of those is to draft the structure of your notebook in advance. When you work on something new, e.g. testing, put it into a separate section. It usually a good idea to plan the structure of your notebook in advance, and even use separate notebooks for different stages of your work. For now, put the experiments with testing into a separate section of the notebook.
The answer that just came to your head, in all likelyhood, sounds similar to this: “I would pass a simple DataFrame to this function and check manually that the returned maximum value is correct”. It makes perfect sense, and, perhaps, may work with a function as simple as ours:
test_input = pd.DataFrame(data=[[1, 5, 3], [7, 8, 9], [3, 4, 1]], columns=list("abc"))
test_output = 7
models.max_mag(test_input, "a") == test_output
True
But now let’s make the task more realistic and recall our original objective: to get maximum values of the light curves in all bands. We can write a function for this as well:
### Get maximum values for all bands
def calc_stat(lc, bands, mag_col):
# Define an empty dictionary where we will store the results
stat = {}
# For each band get the maximum value and store it in the dictionary
for b in bands:
stat[b + "_max"] = models.max_mag(lc[b], mag_col)
return stat
And then construct the test data:
df1 = pd.DataFrame(data=[[1, 5, 3], [7, 8, 9], [3, 4, 1]], columns=list("abc"))
df2 = pd.DataFrame(data=[[7, 3, 2], [8, 4, 2], [5, 6, 4]], columns=list("abc"))
df3 = pd.DataFrame(data=[[2, 6, 3], [1, 3, 6], [8, 9, 1]], columns=list("abc"))
test_input = {"df1": df1, "df2": df2, "df3": df3}
test_output = {"df1_max": 8, "df12_max": 6, "df3_max": 8}
test_output == calc_stat(test_input, ["df1", "df2", "df3"], "b")
See what kind of output this code produces.
What went wrong?
If you just copied the code above, you got
False. Try to find out what is wrong with ourcalc_statfunction.Solution
Our
calc_statfunction is fine. Ourtest_outputcontains two errors. This example highlights an important point: as well as making sure our code is returning correct answers, we also need to ensure the tests themselves are also correct. Otherwise, we may go on to fix our code only to return an incorrect result that appears to be correct. So a good rule is to make tests simple enough to understand so we can reason about both the correctness of our tests as well as our code. Otherwise, our tests hold little value.
Our crude test failed and didn’t even inform us about the reasons they failed. Surely there must be a better way to do this.
Testing Frameworks
The example above shows that manually constructing even a simple test for a fairly simple function can be tedious, and may produce new errors instead of fixing the old ones. Besides, we would like to test many functions in various scenarios, and for a complex function or a library, a test suite - a set of tests - can include dozens of tests. Obviously, running them one by one in a notebook is not a good idea, so we need a tool to automatize this process and to obtain a comprehensive report on which of the tests were passed and which failed. We’d also prefer to have something that tells us what exactly went wrong.
A solution for these tasks is called unit testing frameworks. In such a framework we define the tests we want to run as functions, and the framework automatically runs each of these functions in turn, summarising the outputs. Since most people don’t enjoy writing tests, the unit testing fraimworks aim to make it simple to:
- Add or change tests,
- Understand the tests that have already been written,
- Run those tests, and
- Understand those tests’ results.
Test results must also be reliable. If a testing tool says that code is working when it’s not, or reports problems when there actually aren’t any, people will lose faith in it and stop using it.
We will use a testing framework called pytest. It is a Python
package that can be installed, as usual, using pip:
$ python -m pip install pytest
Why Use pytest over unittest?
We could alternatively use another Python unit test framework, unittest, which has the advantage of being installed by default as part of Python. This is certainly a solid and established option, however pytest has many distinct advantages, particularly for learning, including:
- unittest requires additional knowledge of object-oriented paradigm to write unit tests, whereas in pytest these are written in simpler functions so is easier to learn
- Being written using simpler functions, pytest’s scripts are more concise and contain less boilerplate, and thus are easier to read
- pytest output, particularly in regard to test failure output, is generally considered more helpful and readable
- pytest has a vast ecosystem of plugins available if ever you need additional testing functionality
- unittest-style unit tests can be run from pytest out of the box!
You can have a look at the tests written with pytest and unittest in the pandas and LSST rubin_sim repositories correspondingly. Once you’ve become accustomed to object-oriented programming you may find unittest a better fit for a particular project or team, so you may want to revisit it at a later date!
pytest requires that we put our tests into a separate .py file.
We already have some tests in tests/test_models.py:
"""Tests for statistics functions within the Model layer."""
import pandas as pd
def test_max_mag_integers():
# Test that max_mag function works for integers
from lcanalyzer.models import max_mag
test_input_df = pd.DataFrame(data=[[1, 5, 3], [7, 8, 9], [3, 4, 1]], columns=list("abc"))
test_input_colname = "a"
test_output = 7
assert max_mag(test_input_df, test_input_colname) == test_output
...
The first function represent the same test case as the one we tried first in our notebook. However, it has a different format:
- we import the function we test right inside the test function, for clarity of testing environment;
- then we specify our test input and output;
- and then we run our testing using assert keyword.
We haven’t met with assert keyword before, however, it is essential for developing,
debugging and testing of robust and reliable code. assert keyword is responsible
for checking if some condition
is true. If it is true, nothing happens and the execution of the code continues. However,
if the condition is not fullfilled, an AssertionError occurs. When you write
your own assert checks, you can use the following syntax:
assert condition, message
And testing frameworks already have their own implementations of various assertions,
for example those that can check if two dictionaries are the same (and then inform us
where exactly they differ), if two variables are of the same type and so on. Apart from that,
some other packages, including numpy and pandas, have testing modules that allow you
to compare numpy arrays, DataFrames, Series and so on.
Running Tests
Now we can run these tests in the command line using pytest:
$ python -m pytest tests/test_models.py
Here, we use -m to invoke the pytest installed module,
and specify the tests/test_models.py file to run the tests in that file explicitly.
Why Run Pytest Using
python -mand Notpytest?Another way to run
pytestis via its own command, so we could try to usepytest tests/test_models.pyon the command line instead, but this would lead to aModuleNotFoundError: No module named 'lcanalyzer'. This is because using thepython -m pytestmethod adds the current directory to its list of directories to search for modules, whilst usingpytestdoes not - thelcanalyzersubdirectory’s contents are not ‘seen’, hence theModuleNotFoundError. There are ways to get around this with various methods, but we’ve usedpython -mfor simplicity.
============================= test session starts ==============================
platform linux -- Python 3.11.5, pytest-8.0.0, pluggy-1.4.0
rootdir: /home/alex/InterPython_Workshop_Example
plugins: anyio-4.2.0
collected 2 items
tests/test_models.py .. [100%]
============================== 2 passed in 0.44s ===============================
Pytest looks for functions whose names also start with the letters ‘test_’ and runs each one.
Notice the .. after our test script:
- If the function completes without an assertion being triggered,
we count the test as a success (indicated as
.). - If an assertion fails, or we encounter an error,
we count the test as a failure (indicated as
F). The error is included in the output so we can see what went wrong.
So if we have many tests, we essentially get a report indicating which tests succeeded or failed.
Exercise: Write Some Unit Tests
We already have a couple of test cases in
tests/test_models.pythat test themax_mag()function. Looking atlcanalyzer/models.py, write at least two new test cases that test themean_mag()andmin_mag()functions, adding them totests/test_models.py. Here are some hints:
- You could choose to format your functions very similarly to
max_mag(), defining test input and expected result arrays followed by the equality assertion.- Try to choose cases that are suitably different, and remember that these functions take a DataFrame and return a float corresponding to a chosen column
- Experiment with the functions in a notebook cell in
test-development.ipynbto make sure your test result is what you expect the function to return for a given input. Don’t forget to put your new test intests/test_models.pyonce you think it’s ready!Once added, run all the tests again with
python -m pytest tests/test_models.py, and you should also see your new tests pass.Solution
def test_min_mag_negatives(): # Test that min_mag function works for negatives from lcanalyzer.models import min_mag test_input_df = pd.DataFrame(data=[[-7, -7, -3], [-4, -3, -1], [-1, -5, -3]], columns=list("abc")) test_input_colname = "b" test_output = -7 assert min_mag(test_input_df, test_input_colname) == test_outputdef test_mean_mag_integers(): # Test that mean_mag function works for negatives from lcanalyzer.models import mean_mag test_input_df = pd.DataFrame(data=[[-7, -7, -3], [-4, -3, -1], [-1, -5, -3]], columns=list("abc")) test_input_colname = "a" test_output = -4. assert mean_mag(test_input_df, test_input_colname) == test_output
Optional Exercise: Write a Unit Test for the
calc_statfunctionIf you have some time left, extract our
calc_statfunction into themodels.pyfile and write a test for this function, using the (correct) test input and output from our experiments earlier.
The big advantage is that as our code develops we can update our test cases and commit them back, ensuring that ourselves (and others) always have a set of tests to verify our code at each step of development. This way, when we implement a new feature, we can check a) that the feature works using a test we write for it, and b) that the development of the new feature doesn’t break any existing functionality.
What About Testing for Errors?
There are some cases where seeing an error is actually the correct behaviour,
and Python allows us to test for exceptions.
Add this test in tests/test_models.py:
import pytest
def test_max_mag_strings():
# Test for TypeError when passing a string
from lcanalyzer.models import max_mag
test_input_colname = "b"
with pytest.raises(TypeError):
error_expected = max_mag('string', test_input_colname)
Note that you need to import the pytest library at the top of our test_models.py file
with import pytest so that we can use pytest’s raises() function.
Run all your tests as before.
Since we’ve installed pytest to our environment,
we should also regenerate our requirements.txt:
$ pip3 freeze > requirements.txt
Finally, let’s commit our new test_models.py file,
requirements.txt file,
and test cases to our test-suite branch,
and push this new branch and all its commits to GitHub:
$ git add requirements.txt tests/test_models.py
$ git commit -m "Add initial test cases for mean_mag() and min_mag()"
$ git push -u origin test-suite
Why Should We Test Invalid Input Data?
Testing the behaviour of inputs, both valid and invalid, is a really good idea and is known as data validation. Even if you are developing command line software that cannot be exploited by malicious data entry, testing behaviour against invalid inputs prevents generation of erroneous results that could lead to serious misinterpretation (as well as saving time and compute cycles which may be expensive for longer-running applications). It is generally best not to assume your user’s inputs will always be rational.
What About Unit Testing in Other Languages?
Other unit testing frameworks exist for Python, including Nose2 and Unittest, and the approach to unit testing can be translated to other languages as well, e.g. pFUnit for Fortran, JUnit for Java (the original unit testing framework), Catch or gtest for C++, etc.
Key Points
The three main types of automated tests are unit tests, functional tests and regression tests.
We can write unit tests to verify that functions generate expected output given a set of specific inputs.
It should be easy to add or change tests, understand and run them, and understand their results.
We can use a unit testing framework like Pytest to structure and simplify the writing of tests in Python.
We should test for expected errors in our code.
Testing program behaviour against both valid and invalid inputs is important and is known as data validation.
Scaling Up Unit Testing
Overview
Teaching: 10 min
Exercises: 5 minQuestions
How can we make it easier to write lots of tests?
How can we know how much of our code is being tested?
Objectives
Use parameterisation to automatically run tests over a set of inputs
Use code coverage to understand how much of our code is being tested using unit tests
Introduction
We’re starting to build up a number of tests that test the same function, but just with different parameters. However, continuing to write a new function for every single test case isn’t likely to scale well as our development progresses. How can we make our job of writing tests more efficient? And importantly, as the number of tests increases, how can we determine how much of our code base is actually being tested?
Parameterising Our Unit Tests
So far, we’ve been writing a single function for every new test we need. But when we simply want to use the same test code but with different data for another test, it would be great to be able to specify multiple sets of data to use with the same test code. Test parameterisation gives us this.
So instead of writing a separate function for each different test,
we can parameterise the tests with multiple test inputs.
For example, in tests/test_models.py let us rewrite
the test_max_mag_zeros() and test_max_mag_integers()
into a single test function:
@pytest.mark.parametrize(
"test_df, test_colname, expected",
[
(pd.DataFrame(data=[[1, 5, 3],
[7, 8, 9],
[3, 4, 1]],
columns=list("abc")),
"a",
7),
(pd.DataFrame(data=[[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
columns=list("abc")),
"b",
0),
])
def test_max_mag(test_df, test_colname, expected):
"""Test max function works for array of zeroes and positive integers."""
from lcanalyzer.models import max_mag
assert max_mag(test_df, test_colname) == expected
Here, we use Pytest’s mark capability to add metadata to this specific test -
in this case, marking that it’s a parameterised test.
parameterize() function is actually a
Python decorator.
A decorator, when applied to a function,
adds some functionality to it when it is called, and here,
what we want to do is specify multiple input and expected output test cases
so the function is called over each of these inputs automatically when this test is called.
We specify these as arguments to the parameterize() decorator,
firstly indicating the names of these arguments that will be
passed to the function (test_df, test_colname, expected),
and secondly the actual arguments themselves that correspond to each of these names -
the input data (the test_df and test_colname arguments),
and the expected result (the expected argument).
In this case, we are passing in two tests to test_max_mag() which will be run sequentially.
So our first test will run max_mag() on pd.DataFrame(data=[[1, 5, 3],
[7, 8, 9],
[3, 4, 1]],
columns=list("abc")) (our test_df argument),
and check to see if it equals 7 (our expected argument) with test_colname set to 'a'.
Similarly, our second test will run max_mag()
with pd.DataFrame(data=[[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
columns=list("abc")) and check it produces 0 with test_colname set to 'b'.
The big plus here is that we don’t need to write separate functions for each of the tests - our test code can remain compact and readable as we write more tests and adding more tests scales better as our code becomes more complex.
Exercise: Write Parameterised Unit Tests
Rewrite your test functions for
mean_mag()to be parameterised, adding in new test cases. A suggestion: instead of filling the DataFrames manually, you can usenumpy.random.randint()andnumpy.random.rand()functions. When developing these tests you are likely to see a situation when the expected value is a float. In some cases your code may produce the output that has some uncertainty; how do you test such functions? For this situation,pytesthas a special function calledapprox. It allow you to assert similar values with some degree of precision; e.g.assert func(input) == pytest.approx(expected,0.01))returnsTruein when(expected-0.01)<=func(input)<=(expected+0.01). Similar solutions exist fornumpy.testingand other testing tools.Solution
... # Parametrization for mean_mag function testing @pytest.mark.parametrize( "test_df, test_colname, expected", [ (pd.DataFrame(data=[[1, 5, 3], [7, 8, 9], [3, 4, 1]], columns=list("abc")), "a", pytest.approx(3.66,0.01)), (pd.DataFrame(data=[[0, 0, 0], [0, 0, 0], [0, 0, 0]], columns=list("abc")), "b", 0), ]) def test_mean_mag(test_df, test_colname, expected): """Test mean function works for array of zeroes and positive integers.""" from lcanalyzer.models import mean_mag assert mean_mag(test_df, test_colname) == expected
Let’s commit our revised test_models.py file and test cases to our test-suite branch
(but don’t push them to the remote repository just yet!):
$ git add tests/test_models.py
$ git commit -m "Add parameterisation mean, min, max test cases"
Code Coverage - How Much of Our Code is Tested?
Pytest can’t think of test cases for us.
We still have to decide what to test and how many tests to run.
Our best guide here is economics:
we want the tests that are most likely to give us useful information that we don’t already have.
For example, if testing our max_mag function with a DataFrame filled with integers works,
there’s probably not much point testing the same function with a DataFrame filled with other integers,
since it’s hard to think of a bug that would show up in one case but not in the other. Note, however,
that for other function this statement may be incorrect (e.g. if your function is supposed to discard values
above a certain threshold, and your test case input does not contain such values at all).
Now, we should try to choose tests that are as different from each other as possible, so that we force the code we’re testing to execute in all the different ways it can - to ensure our tests have a high degree of code coverage.
A simple way to check the code coverage for a set of tests is
to use pytest to tell us how many statements in our code are being tested.
By installing a Python package to our virtual environment called pytest-cov
that is used by Pytest and using that, we can find this out:
$ pip3 install pytest-cov
$ python -m pytest --cov=lcanalyzer.models tests/test_models.py
So here, we specify the additional named argument --cov to pytest
specifying the code to analyse for test coverage.
==================================== test session starts ====================================
platform linux -- Python 3.11.5, pytest-8.0.0, pluggy-1.4.0
rootdir: /home/alex/InterPython_Workshop_Example
plugins: anyio-4.2.0, cov-4.1.0
collected 9 items
tests/test_models_full.py ......... [100%]
---------- coverage: platform linux, python 3.11.5-final-0 -----------
Name Stmts Miss Cover
------------------------------------------
lcanalyzer/models.py 12 1 92%
------------------------------------------
TOTAL 12 1 92%
===================================== 9 passed in 0.70s =====================================
Here we can see that our tests are doing well - 92% of statements in lcanalyzer/models.py have been executed.
But which statements are not being tested?
The additional argument --cov-report term-missing can tell us:
$ python -m pytest --cov=lcanalyzer.models --cov-report term-missing tests/test_models.py
...
==================================== test session starts ====================================
platform linux -- Python 3.11.5, pytest-8.0.0, pluggy-1.4.0
rootdir: /home/alex/InterPython_Workshop_Example
plugins: anyio-4.2.0, cov-4.1.0
collected 11 items
tests/test_models.py .. [ 18%]
tests/test_models_full.py ......... [100%]
---------- coverage: platform linux, python 3.11.5-final-0 -----------
Name Stmts Miss Cover Missing
----------------------------------------------------
lcanalyzer/models.py 12 1 92% 20
----------------------------------------------------
TOTAL 12 1 92%
==================================== 11 passed in 0.71s =====================================
...
So there’s still one statement not being tested at line 20,
and it turns out it’s in the function load_dataset().
Here we should consider whether or not to write a test for this function,
and, in general, any other functions that may not be tested.
Of course, if there are hundreds or thousands of lines that are not covered
it may not be feasible to write tests for them all.
But we should prioritise the ones for which we write tests, considering
how often they’re used,
how complex they are,
and importantly, the extent to which they affect our program’s results.
Again, we should also update our requirements.txt file with our latest package environment,
which now also includes pytest-cov, and commit it:
$ pip3 freeze > requirements.txt
$ cat requirements.txt
You’ll notice pytest-cov and coverage have been added.
Let’s commit this file and push our new branch to GitHub:
$ git add requirements.txt
$ git commit -m "Add coverage support"
$ git push origin test-suite
What about Testing Against Indeterminate Output?
What if your implementation depends on a degree of random behaviour? This can be desired within a number of applications, particularly in simulations or machine learning. So how can you test against such systems if the outputs are different when given the same inputs?
One way is to remove the randomness during testing. For those portions of your code that use a language feature or library to generate a random number, you can instead produce a known sequence of numbers instead when testing, to make the results deterministic and hence easier to test against. You could encapsulate this different behaviour in separate functions, methods, or classes and call the appropriate one depending on whether you are testing or not. This is essentially a type of mocking, where you are creating a “mock” version that mimics some behaviour for the purposes of testing.
Another way is to control the randomness during testing to provide results that are deterministic - the same each time. Implementations of randomness in computing languages, including Python, are actually never truly random - they are pseudorandom: the sequence of ‘random’ numbers are typically generated using a mathematical algorithm. A seed value is used to initialise an implementation’s random number generator, and from that point, the sequence of numbers is actually deterministic. Many implementations just use the system time as the default seed, but you can set your own. By doing so, the generated sequence of numbers is the same, e.g. using Python’s
randomlibrary to randomly select a sample of ten numbers from a sequence between 0-99:import random random.seed(1) print(random.sample(range(0, 100), 10)) random.seed(1) print(random.sample(range(0, 100), 10))Will produce:
[17, 72, 97, 8, 32, 15, 63, 57, 60, 83] [17, 72, 97, 8, 32, 15, 63, 57, 60, 83]So since your program’s randomness is essentially eliminated, your tests can be written to test against the known output. The trick of course, is to ensure that the output being testing against is definitively correct!
The other thing you can do while keeping the random behaviour, is to test the output data against expected constraints of that output. For example, if you know that all data should be within particular ranges, or within a particular statistical distribution type (e.g. normal distribution over time), you can test against that, conducting multiple test runs that take advantage of the randomness to fill the known “space” of expected results. Note that this isn’t as precise or complete, and bear in mind this could mean you need to run a lot of tests which may take considerable time.
Package-specific asserts
Let us add a new function to our jupyter notebook called calc_stats()
that will calculate for us all three statistical indicators (min, max and mean) for all
bands of our light curve.
(Make sure you create a new feature branch for this work off your develop branch.)
def calc_stats(lc, bands, mag_col):
# Calculate max, mean and min values for all bands of a light curve
stats = {}
for b in bands:
stat = {}
stat["max"] = models.max_mag(lc[b], mag_col)
stat["mean"] = models.max_mag(lc[b], mag_col)
stat["min"] = models.mean_mag(lc[b], mag_col)
stats[b] = stat
return pd.DataFrame.from_records(stats)
Note: there are intentional mistakes in the above code, which will be detected by further testing and code style checking below so bear with us for the moment!
This code accepts a dictionary of DataFrames that contain observations of a single object in all bands.
Then this code iterates through the bands, calculating the requested statistical values and storing them
in a dictionary. At the end, these dictionaries are converted into a DataFrame, where column names are the
keys of the original lc dictionary, and the index (‘row names’) are the names of the statistics (‘max’,
‘mean’ and ‘min’). Pass one of our previously designed light curves to this function
to see that the result is an accurate and informative pandas table.
Can’t we save them directly into a DataFrame?
Technically, we can. However, editing DataFrames row by row or element by element is inefficient from the computational point of view. For this reason, when creating a frame row by row is inevitable, storing data in a list, dictionary or array and then converting them in a DataFrame is the preferred solution. It is also worth noting that in many cases iterations in a loop through the rows of some kind of a table can be avoided entirely with a better design of the algorithm.
Now let’s design a test case for this function:
test_cols = list("abc")
test_dict = {}
test_dict["df0"] = pd.DataFrame(
data=[[8, 8, 0],
[0, 1, 1],
[2, 3, 1],
[7, 9, 7]], columns=test_cols
)
test_dict["df1"] = pd.DataFrame(
data=[[3, 8, 2],
[3, 8, 0],
[3, 9, 8],
[8, 2, 5]], columns=test_cols
)
test_dict["df2"] = pd.DataFrame(
data=[[8, 4, 3],
[7, 6, 3],
[4, 2, 9],
[6, 4, 0]], columns=test_cols
)
Remember, that we don’t have to fill the data manually, but can use built-in numpy
random generator. For example, for the data above size = (4,3); np.random.randint(0, 10, size)
was used.
The expected output for these data will look like this:
test_output = pd.DataFrame(data=[[9,9,6],[5.25,6.75,4.],[1,2,2]],columns=['df0','df1','df2'],index=['max','mean','min'])
Finally, we can use assert statement to check if our function produces what we expect…
assert calc_stats(test_dict, test_dict.keys(), 'b') == test_output
…and get a ValueError:
...
ValueError: The truth value of a DataFrame is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
The reason for this is that assert takes a condition that produces a single boolean value,
but using == for two DataFrames results in an element-wise comparison and produces a DataFrame
filled with booleans.
This is the case when we need to use a more powerful assert function, the one that is developed specifically
for a certain variable type. Pandas has its own module called testing that contains a number of type-specific
assert functions. Let’s import this module:
import pandas.testing as pdt
And use assert_frame_equal function that can compare DataFrames in a meaningful way:
pdt.assert_frame_equal(calc_stats(test_dict, test_dict.keys(), 'b'),
test_output,
check_exact=False,
atol=0.01)
The first two arguments of this function are just what we would expect: the call of our calc_stats
function and the expected test_output. assert_frame_equal will be comparing these two DataFrames.
The next two arguments allow this function to compare the DataFrames with only some degree of precision.
This precision is determined by the argument atol, which stands for ‘absolute tolerance’. The DataFrames
will be considered equal if their elements differ no more than by atol value. This is similar to the
pytest.approx that we encountered in the previous episodes.
This assertion is falining with an error message: apparently, our function produces mean that equals 9.0
instead of 5.25.
...
AssertionError: DataFrame.iloc[:, 0] (column name="df0") are different
DataFrame.iloc[:, 0] (column name="df0") values are different (66.66667 %)
[index]: [max, mean, min]
[left]: [9.0, 9.0, 5.25]
[right]: [9.0, 5.25, 1.0]
At positional index 1, first diff: 9.0 != 5.25
Apparently, there are differences between the two DataFrames in the column ‘df0’; the values in the ‘max’ row are the same, but the ‘mean’ and ‘min’ values are different. Going back to the code of the function, we discover that these two lines:
...
stat["mean"] = models.max_mag(lc[b], mag_col)
stat["min"] = models.mean_mag(lc[b], mag_col)
...
use incorrect functions - a common case when e.g. part of the code was copy-pasted. Now we can fix these errors and relaunch the tests to make sure everything else is correct.
Key Points
We can assign multiple inputs to tests using parametrisation.
It’s important to understand the coverage of our tests across our code.
Writing unit tests takes time, so apply them where it makes the most sense.
Robust Software with Testing Approaches
Overview
Teaching: 20 min
Exercises: 10 minQuestions
How can we make our programs more resilient to failure?
Can we use testing to speed up our work?
Objectives
Describe and identify edge and corner test cases and explain why they are important
Apply defensive programming techniques to improve robustness of a program
Learn what Test Driven Development is
Corner or Edge Cases
The test cases that we have written so far are parameterised with a fairly standard DataFrames filled with random integers or floats. However, when writing your test cases, it is important to consider parameterising them by unusual or extreme values, in order to test all the edge or corner cases that your code could be exposed to in practice. Generally speaking, it is at these extreme cases that you will find your code failing, so it’s beneficial to test them beforehand.
What is considered an “edge case” for a given component depends on
what that component is meant to do.
For numerical values, extreme cases could be zeros,
very large or small values,
not-a-number (NaN) or infinity values.
Since we are specifically considering arrays of values,
an edge case could be that all the numbers of the array are equal.
For all the given edge cases you might come up with, you should also consider their likelihood of occurrence. It is often too much effort to exhaustively test a given function against every possible input, so you should prioritise edge cases that are likely to occur. Let’s consider a new function, which purpose is to normalize a single light curve:
def normalize_lc(df,mag_col):
# Normalize a single light curve
min = min_mag(df,mag_col)
max = max_mag((df-min),mag_col)
lc = (df[mag_col]-min)/max
return lc
For a function like this, a common edge case might be the occurrence of zeros, and the case where all the values of the array are the same. Indeed, if we passed to such a function a ‘light curve’ where all measurements are zeros, we would expect to have zeros in return. However, since we have division in this function, it will return and array of ‘NaN’ instead of this.
With this in mind,
let us create a test test_normalize_lc with parametrization
corresponding to an input array of random integers, an input array of all 0,
and an input array of all 1.
# Parametrization for normalize_lc function testing
@pytest.mark.parametrize(
"test_input_df, test_input_colname, expected",
[
(pd.DataFrame(data=[[8, 9, 1],
[1, 4, 1],
[1, 2, 4],
[1, 4, 1]],
columns=list("abc")),
"b",
pd.Series(data=[1,0.285,0,0.285])),
(pd.DataFrame(data=[[1, 1, 1],
[1, 1, 1],
[1, 1, 1],
[1, 1, 1]],
columns=list("abc")),
"b",
pd.Series(data=[0.,0.,0.,0.])),
(pd.DataFrame(data=[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
columns=list("abc")),
"b",
pd.Series(data=[0.,0.,0.,0.])),
])
def test_normalize_lc(test_input_df, test_input_colname, expected):
"""Test how normalize_lc function works for arrays of positive integers."""
from lcanalyzer.models import normalize_lc
import pandas.testing as pdt
pdt.assert_series_equal(normalize_lc(test_input_df,test_input_colname),expected,check_exact=False,atol=0.01,check_names=False)
Pay attention, that since this our normalize_lc function returns a pandas.Series, we have to use the corresponding assert function
(pdt.assert_series_equal). Another thing to pay attention to is the arguments of this function. Not only we specify the atol for
ensuring that there will be no issues when comparing floats, but also set check_names=False, since by default the Series returned from
the normalize_lc function will have the name of the column for which we performed the normalization. Custom assert functions, such as
assert_series_equal, often take a large number of arguments that specify which parameters of the objects have to be compared. E.g. you can
opt out of comparing the dtypes of a Series, the column orders of a DataFrame and so on.
Running the tests now from the command line results in the following assertion error,
due to the division by zero as we predicted. Note that not only the test case with all zeros
fails, but also the test with all ones too, due to the extraction of the min value!
E AssertionError: Series are different
E
E Series values are different (100.0 %)
E [index]: [0, 1, 2, 3]
E [left]: [nan, nan, nan, nan]
E [right]: [0.0, 0.0, 0.0, 0.0]
E At positional index 0, first diff: nan != 0.0
testing.pyx:173: AssertionError
====================================================================================== short test summary info ======================================================================================
FAILED tests/test_models_full.py::test_normalize_lc[test_input_df1-b-expected1] - AssertionError: Series are different
FAILED tests/test_models_full.py::test_normalize_lc[test_input_df2-b-expected2] - AssertionError: Series are different
How can we fix this? For example, we can replace all the NaNs in the
return Series with zeros using pandas function fillna.
...
def normalize_lc(df,mag_col):
# Normalize a single light curve
min = min_mag(df,mag_col)
max = max_mag((df-min),mag_col)
lc = (df[mag_col]-min)/max
lc = lc.fillna(0)
return lc
...
Defensive Programming
In the previous section, we made a few design choices for our normalize_lc function:
- We are implicitly converting any
NaNto 0, - Normalising a constant array of magnitudes in an identical array of 0s,
- We don’t warn the user of any of these situations.
This could have be handled differently. We might decide that we do not want to silently make these changes to the data, but instead to explicitly check that the input data satisfies a given set of assumptions (e.g. no negative values or no values outside of a certain range) and raise an error if this is not the case. Then we can proceed with the normalisation, confident that our normalisation function will work correctly.
Checking that input to a function is valid via a set of preconditions
is one of the simplest forms of defensive programming
which is used as a way of avoiding potential errors.
Preconditions are checked at the beginning of the function
to make sure that all assumptions are satisfied.
These assumptions are often based on the value of the arguments, like we have already discussed.
However, in a dynamic language like Python
one of the more common preconditions is to check that the arguments of a function
are of the correct type.
Currently there is nothing stopping someone from calling normalize_lc with
a string, a dictionary, or another object that is not a DataFrame, or from
passing a DataFrame filled with strings or lists.
As an example, let us change the behaviour of the normalize_lc() function
to raise an error if some magnitudes are smaller than ‘-90’ (since in astronomical data ‘-99.’ or ‘-99.9’ are
common filler values for ‘NaNs’).
Edit our function by adding a precondition check like so:
...
if any(df[mag_col].abs() > 90):
raise ValueError(mag_col+' contains values with abs() larger than 90!')
...
We can then modify our test function
to check that the function raises the correct exception - a ValueError -
when input to the test contains ‘-99.9’ values.
The ValueError exception
is part of the standard Python library
and is used to indicate that the function received an argument of the right type,
but of an inappropriate value.
In lcanalyzer/models.py
def normalize_lc(df,mag_col):
# Normalize a light curve
if any(df[mag_col].abs() > 90):
raise ValueError(mag_col+' contains values with abs() larger than 90!')
min = min_mag(df,mag_col)
max = max_mag((df-min),mag_col)
lc = (df[mag_col]-min)/max
lc = lc.fillna(0)
return lc
Here we added a condition that if our input data contains values that are larger than 90 or smaller than -90,
we should raise a ValueError with the corresponding message.
In tests/test_models.py
# Parametrization for normalize_lc function testing with ValueError
@pytest.mark.parametrize(
"test_input_df, test_input_colname, expected, expected_raises",
[
(pd.DataFrame(data=[[8, 9, 1],
[1, 4, 1],
[1, 2, 4],
[1, 4, 1]],
columns=list("abc")),
"b",
pd.Series(data=[1,0.285,0,0.285]),
None),
(pd.DataFrame(data=[[1, 1, 1],
[1, 1, 1],
[1, 1, 1],
[1, 1, 1]],
columns=list("abc")),
"b",
pd.Series(data=[0.,0.,0.,0.]),
None),
(pd.DataFrame(data=[[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]],
columns=list("abc")),
"b",
pd.Series(data=[0.,0.,0.,0.]),
None),
(pd.DataFrame(data=[[8, 9, 1],
[1, -99.9, 1],
[1, 2, 4],
[1, 4, 1]],
columns=list("abc")),
"b",
pd.Series(data=[1,0.285,0,0.285]),
ValueError),
])
def test_normalize_lc(test_input_df, test_input_colname, expected,expected_raises):
"""Test how normalize_lc function works for arrays of positive integers."""
from lcanalyzer.models import normalize_lc
import pandas.testing as pdt
if expected_raises is not None:
with pytest.raises(expected_raises):
pdt.assert_series_equal(normalize_lc(test_input_df,test_input_colname),expected,check_exact=False,atol=0.01,check_names=False)
else:
pdt.assert_series_equal(normalize_lc(test_input_df,test_input_colname),expected,check_exact=False,atol=0.01,check_names=False)
And in the test_models we had to add to our parametrization a new function argument
called expected_raises, which is equal to None
for the test cases where our function should not invoke any raises. In the testing function itself
we are adding an if statement to separately handling the situation when a raise is expected.
Be sure to commit your changes so far and push them to GitHub.
Optional Exercise: Add a Precondition to Check the Correct Type and Column Names
Add preconditions to check that input data is
DataFrameobject and that its columns contain the column for which we have to perform normalization. Add corresponding tests to check that the function raises the correct exception. You will find the Python functionisinstanceuseful here, as well as the Python exceptionTypeError. Once you are done, commit your new files, and push the new commits to your remote repository on GitHub.
If you do the challenge, again, be sure to commit your changes and push them to GitHub.
You should not take it too far by trying to code preconditions for every conceivable eventuality.
You should aim to strike a balance between
making sure you secure your function against incorrect use,
and writing an overly complicated and expensive function
that handles cases that are likely never going to occur.
For example, it would be sensible to validate the values of your
light curve measurements
when it is actually read from the file,
and therefore there is no reason to test this again in normalize_lc or
any of our functions related to statistics.
You can also decide against adding explicit preconditions in your code,
and instead state the assumptions and limitations of your code
for users of your code in the docstring
and rely on them to invoke your code correctly.
This approach is useful when explicitly checking the precondition is too costly.
Test Driven Development
In the previous episodes we learnt how to create unit tests to make sure our code is behaving as we intended. Test Driven Development (TDD) is an extension of this. If we can define a set of tests for everything our code needs to do, then why not treat those tests as the specification.
With Test Driven Development, the idea is to write our tests first and only write enough code to make the tests pass. It is done at the level of individual features - define the feature, write the tests, write the code. The main advantages are:
- It forces us to think about how our code will be used before we write it
- It prevents us from doing work that we don’t need to do, e.g. “I might need this later…”
- It forces us to test that the tests fail before we’ve implemented the code, meaning we don’t inadvertently forget to add the correct asserts.
You may also see this process called Red, Green, Refactor: ‘Red’ for the failing tests, ‘Green’ for the code that makes them pass, then ‘Refactor’ (tidy up) the result.
Trying the TDD approach
Add a new function to
models.pycalledstd_magthat calculates the standard deviation of an input lightcurve. Instead of starting by writing the function, employ the Red, Green, Refactor approach and start by writing the tests. Consider corner and edge cases and use what we’ve learned about scaling up unit tests using theparameterizedecorator.Solution
Let’s start by copying our parameterized tests for
mean_magbut add a new edge case for an input array that includes NaNs.import numpy as np @pytest.mark.parametrize( "test_df, test_colname, expected", [ (pd.DataFrame(data=[[1, 5, 3], [7, 8, 9], [3, 4, 1]], columns=list("abc")), "a", np.nanstd([1, 7, 3])), (pd.DataFrame(data=[[0, 0, 0], [0, 0, 0], [0, 0, 0]], columns=list("abc")), "b", np.nanstd([0, 0, 0])), (pd.DataFrame(data=[[np.nan, 1, 0], [0, np.nan, 1], [1, 1, np.nan]], columns=list("abc")), "a", np.nanstd([np.nan, 0, 1])), ]) def test_std_mag(test_df, test_colname, expected): """Test standard dev function works like numpy.nanstd for array of zeroes, positive integers, and NaNs""" from lcanalyzer.models import std_mag assert std_mag(test_df, test_colname) == expectedSuppose the intended behavior of
std_magshould be to return the same result as usingnumpy.nanstd()on the input column. In this case, our test will fail if we use the.std()method of the input dataframe. This is because the divisor used innumpy.nanstd()isN - ddofwhere N is the number of elements and “ddof” (delta degrees of freedom) is zero by default, but is set to 1 by default when usingpd.DataFrame().std(). Addingddof=0as an argument to the.std()call in our function fixes the error.def std_mag(data,mag_col): """Calculate the standard devation of a lightcurve. :param data: pd.DataFrame with observed magnitudes for a single source. :param mag_col: a string with the name of the column for calculating the standard devation. :returns: The standard devation of the column. """ return data[mag_col].std(ddof=0)
Limits to Testing
Like any other piece of experimental apparatus, a complex program requires a much higher investment in testing than a simple one. Putting it another way, a small script that is only going to be used once, to produce one figure, probably doesn’t need separate testing: its output is either correct or not. A linear algebra library that will be used by thousands of people in twice that number of applications over the course of a decade, on the other hand, definitely does. The key is identify and prioritise against what will most affect the code’s ability to generate accurate results.
It’s also important to remember that unit testing cannot catch every bug in an application, no matter how many tests you write. To mitigate this manual testing is also important. Also remember to test using as much input data as you can, since very often code is developed and tested against the same small sets of data. Increasing the amount of data you test against - from numerous sources - gives you greater confidence that the results are correct.
Our software will inevitably increase in complexity as it develops. Using automated testing where appropriate can save us considerable time, especially in the long term, and allows others to verify against correct behaviour.
Key Points
Ensure that unit tests check for edge and corner cases too.
Use preconditions to ensure correct behaviour of code.
Write tests before the code itself to think of the functionality and desired behaviour in advance.
Section 3: Automatizing code quality checks
Overview
Teaching: 5 min
Exercises: 0 minQuestions
How to set up automatic testing for all contributors of the project?
How to enforce coding style conventions?
How to estimate computational effectiveness of the software and find bottlenecks?
Objectives
Introduce the tools, techniques, and best practices for automatizing your work on ensuring the quality of the software.
After learning what testing is and how to write tests manually, we will learn how to make sure that you do not skip the testing fase in a hurry. We also cover how to profile the time and computational resources your software requires.
In this section we will:
- Automatically run a set of unit tests using GitHub Actions - a Continuous Integration infrastructure that allows us to automate tasks when things happen to our code, such as running those tests when a new commit is made to a code repository.
- Use Pylint to check code style conventions.
- Use Jupyter magic commands to measure performance time of the code.
- Use library SnakeViz to profile resources taken by the software.
Key Points
Running tests every time when the code is updates is tiresome, and we can be tempted to skip this step. We should use automatic Continuous Integration tools, such as GitHub Actions, to make sure that the tests are executed regularly.
Continuous Integration also allows us to set up an automatic code style checks.
To check how efficient our code is and find bottlenecks, we can use Jupyter Lab built-in magic commands and Python libraries, such as cProfile and SnakeViz
Continuous Integration for Automated Testing
Overview
Teaching: 25 min
Exercises: 0 minQuestions
How can I automate the testing of my repository’s code in a way that scales well?
What can I do to make testing across multiple platforms easier?
Objectives
Describe the benefits of using Continuous Integration for further automation of testing
Enable GitHub Actions Continuous Integration for public open source repositories
Use continuous integration to automatically run unit tests and code coverage when changes are committed to a version control repository
Use a build matrix to specify combinations of operating systems and Python versions to run tests over
Introduction
So far we’ve been manually running our tests as we require. Once we’ve made a change, or added a new feature with accompanying tests, we can re-run our tests, giving ourselves (and others who wish to run them) increased confidence that everything is working as expected. Now we’re going to take further advantage of automation in a way that helps testing scale across a development team with very little overhead, using Continuous Integration.
What is Continuous Integration?
The automated testing we’ve done so far only takes into account the state of the repository we have on our own machines. In a software project involving multiple developers working and pushing changes on a repository, it would be great to know holistically how all these changes are affecting our codebase without everyone having to pull down all the changes and test them. If we also take into account the testing required on different target user platforms for our software and the changes being made to many repository branches, the effort required to conduct testing at this scale can quickly become intractable for a research project to sustain.
Continuous Integration (CI) aims to reduce this burden by further automation, and automation - wherever possible - helps us to reduce errors and makes predictable processes more efficient. The idea is that when a new change is committed to a repository, CI clones the repository, builds it if necessary, and runs any tests. Once complete, it presents a report to let you see what happened.
There are many CI infrastructures and services, free and paid for, and subject to change as they evolve their features. We’ll be looking at GitHub Actions - which unsurprisingly is available as part of GitHub.
Continuous Integration with GitHub Actions
A Quick Look at YAML
YAML is a text format used by GitHub Action workflow files. It is also increasingly used for configuration files and storing other types of data, so it’s worth taking a bit of time looking into this file format.
YAML (a recursive acronym which stands for “YAML Ain’t Markup Language”) is a language designed to be human readable. A few basic things you need to know about YAML to get started with GitHub Actions are key-value pairs, arrays, maps and multi-line strings.
So firstly, YAML files are essentially made up of key-value pairs,
in the form key: value, for example:
name: Kilimanjaro
height_metres: 5892
first_scaled_by: Hans Meyer
In general, you don’t need quotes for strings,
but you can use them when you want to explicitly distinguish between numbers and strings,
e.g. height_metres: "5892" would be a string,
but in the above example it is an integer.
It turns out Hans Meyer isn’t the only first ascender of Kilimanjaro,
so one way to add this person as another value to this key is by using YAML arrays,
like this:
first_scaled_by:
- Hans Meyer
- Ludwig Purtscheller
An alternative to this format for arrays is the following, which would have the same meaning:
first_scaled_by: [Hans Meyer, Ludwig Purtscheller]
If we wanted to express more information for one of these values we could use a feature known as maps (dictionaries/hashes), which allow us to define nested, hierarchical data structures, e.g.
...
height:
value: 5892
unit: metres
measured:
year: 2008
by: Kilimanjaro 2008 Precise Height Measurement Expedition
...
So here, height itself is made up of three keys value, unit, and measured,
with the last of these being another nested key with the keys year and by.
Note the convention of using two spaces for tabs, instead of Python’s four.
We can also combine maps and arrays to describe more complex data. Let’s say we want to add more detail to our list of initial ascenders:
...
first_scaled_by:
- name: Hans Meyer
date_of_birth: 22-03-1858
nationality: German
- name: Ludwig Purtscheller
date_of_birth: 22-03-1858
nationality: Austrian
So here we have a YAML array of our two mountaineers, each with additional keys offering more information.
GitHub Actions also makes use of | symbol to indicate a multi-line string
that preserves new lines. For example:
shakespeare_couplet: |
Good night, good night. Parting is such sweet sorrow
That I shall say good night till it be morrow.
They key shakespeare_couplet would hold the full two line string,
preserving the new line after sorrow.
As we’ll see shortly, GitHub Actions workflows will use all of these.
Defining Our Workflow
With a GitHub repository there’s a way we can set up CI
to run our tests automatically when we commit changes.
Let’s do this now by adding a new file to our repository whilst on the test-suite branch.
First, create the new directories .github/workflows:
$ mkdir -p .github/workflows
Making Jupyter Lab show hidden files
By default, Jupyter Lab file manager does not show hidden files and directories. If you prefer to change that, you need to enable a corresponding option in Jupyter Lab configuration file. In the terminal run:
$ jupyter --pathsconfig: /home/alex/.jupyter ... data: /home/alex/.local/share/jupyter ...This command lists the folders in which Jupyter will look for configuration files, ordered by precedence. In all likelyhood, you already have a config file called
jupyter_server_config.pyin the upmost folder:$ ls -l /home/alex/.jupytertotal 84 -rw-rw-r-- 1 alex alex 69714 Jul 1 12:38 jupyter_server_config.py drwxrwxr-x 4 alex alex 4096 Feb 4 14:28 lab ...If not, you can generate it by typing:
$ jupyter server --generate-configNext, open it with any text editor, for example:
$ gedit /home/alex/.jupyter/jupyter_server_config.pyand find
c.ContentsManager.allow_hiddenparameter. By default it is commented out and set toFalse, so you need to uncomment it and change its value toTrue, and then save the file.After that go to the Jupyter Lab window and choose
View > Show hidden files, and hidden files will be available through the Jupyter Lab file browser. It is handy when you need to edit some hidden configuration files or keep track on temporal files created by your code, and if you don’t need it for some particular project, you can always switch it off by uncheckingView > Show hidden files.
This directory is used specifically for GitHub Actions,
allowing us to specify any number of workflows that can be run under a variety of conditions,
which is also written using YAML.
So let’s add a new YAML file called main.yml
(note it’s extension is .yml without the a)
within the new .github/workflows directory:
name: CI
# We can specify which Github events will trigger a CI build
on: push
# now define a single job 'build' (but could define more)
jobs:
build:
# we can also specify the OS to run tests on
runs-on: ubuntu-latest
# a job is a seq of steps
steps:
# Next we need to checkout out repository, and set up Python
# A 'name' is just an optional label shown in the log - helpful to clarify progress - and can be anything
- name: Checkout repository
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: "3.11"
- name: Install Python dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Test with PyTest
run: |
python -m pytest --cov=lcanalyzer.models tests/test_models.py
Note: be sure to create this file as main.yml
within the newly created .github/workflows directory,
or it won’t work!
So as well as giving our workflow a name - CI -
we indicate with on that we want this workflow to run when we push commits to our repository.
The workflow itself is made of a single job named build,
and we could define any number of jobs after this one if we wanted,
and each one would run in parallel.
Next, we define what our build job will do.
With runs-on we first state which operating systems we want to use,
in this case just Ubuntu for now.
We’ll be looking at ways we can scale this up to testing on more systems later.
Lastly, we define the steps that our job will undertake in turn,
to set up the job’s environment and run our tests.
You can think of the job’s environment initially as a blank slate:
much like a freshly installed machine (albeit virtual) with very little installed on it,
we need to prepare it with what it needs to be able to run our tests.
Each of these steps are:
- Checkout repository for the job:
usesindicates that want to use a GitHub Action calledcheckoutthat does this - Set up Python 3.11:
here we use the
setup-pythonAction, indicating that we want Python version 3.11. Note we specify the version within quotes, to ensure that this is interpreted as a complete string. Otherwise, if we wanted to test against for example Python 3.10, by specifying3.10without the quotes, it would be interpreted as the number3.1which - although it’s the same number as3.10- would be interpreted as the wrong version! - Install latest version of pip, dependencies, and our lightcurves package:
In order to locally install our
lcanalyzerpackage it’s good practice to upgrade the version of pip that is present first, then we use pip to install our package dependencies. Once installed, we can usepip3 install -e .as before to install our own package. We userunhere to run theses commands in the CI shell environment - Test with PyTest: lastly, we run
python -m pytest, with the same arguments we used manually before
What about other Actions?
Our workflow here uses standard GitHub Actions (indicated by
actions/*). Beyond the standard set of actions, others are available via the GitHub Marketplace. It contains many third-party actions (as well as apps) that you can use with GitHub for many tasks across many programming languages, particularly for setting up environments for running tests, code analysis and other tools, setting up and using infrastructure (for things like Docker or Amazon’s AWS cloud), or even managing repository issues. You can even contribute your own.
Triggering a Build on GitHub Actions
Now if we commit and push this change a CI run will be triggered:
$ git add .github
$ git commit -m "Add GitHub Actions configuration"
$ git push
Since we are only committing the GitHub Actions configuration file
to the test-suite branch for the moment,
only the contents of this branch will be used for CI.
We can pass this file upstream into other branches (i.e. via merges) when we’re happy it works,
which will then allow the process to run automatically on these other branches.
This again highlights the usefulness of the feature-branch model -
we can work in isolation on a feature until it’s ready to be passed upstream
without disrupting development on other branches,
and in the case of CI,
we’re starting to see its scaling benefits across a larger scale development team
working across potentially many branches.
Checking Build Progress and Reports
Handily, we can see the progress of the build from our repository on GitHub
by selecting the test-suite branch from the dropdown menu
(which currently says main),
and then selecting commits
(located just above the code directory listing on the right,
alongside the last commit message and a small image of a timer).


You’ll see a list of commits for this branch,
and likely see an orange marker next to the latest commit
(clicking on it yields Some checks haven’t completed yet)
meaning the build is still in progress.
This is a useful view, as over time, it will give you a history of commits,
who did them, and whether the commit resulted in a successful build or not.
Hopefully after a while, the marker will turn into a green tick indicating a successful build.
Clicking it gives you even more information about the build,
and selecting Details link takes you to a complete log of the build and its output.
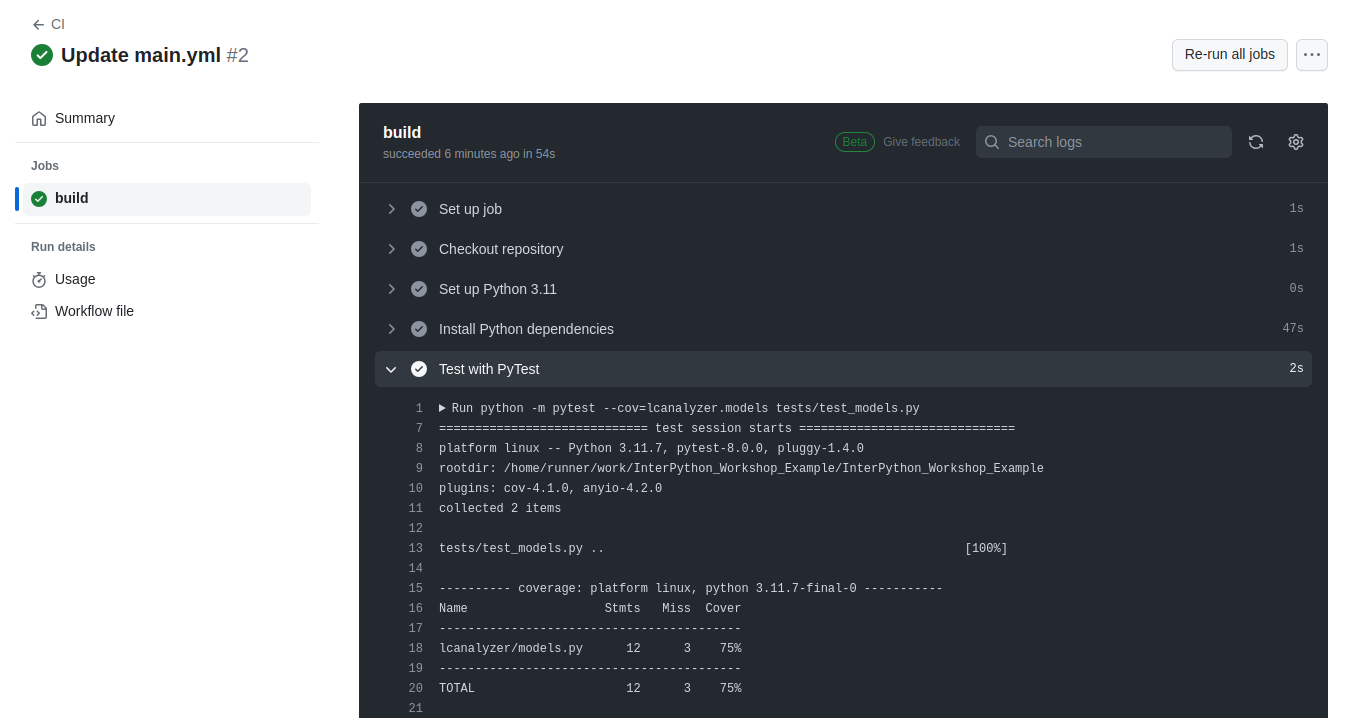
The logs are actually truncated; selecting the arrows next to the entries -
which are the name labels we specified in the main.yml file -
will expand them with more detail, including the output from the actions performed.
GitHub Actions offers these continuous integration features as a completely free service for public repositories, and supplies 2000 build minutes a month on as many private repositories that you like. Paid levels are available too.
Scaling Up Testing Using Build Matrices
Now we have our CI configured and building, we can use a feature called build matrices which really shows the value of using CI to test at scale.
Suppose the intended users of our software use either Ubuntu, Mac OS, or Windows, and either have Python version 3.10 or 3.11 installed, and we want to support all of these. Assuming we have a suitable test suite, it would take a considerable amount of time to set up testing platforms to run our tests across all these platform combinations. Fortunately, CI can do the hard work for us very easily.
Using a build matrix we can specify testing environments and parameters (such as operating system, Python version, etc.) and new jobs will be created that run our tests for each permutation of these.
Let’s see how this is done using GitHub Actions.
To support this, we define a strategy as
a matrix of operating systems and Python versions within build.
We then use matrix.os and matrix.python-version to reference these configuration possibilities
instead of using hardcoded values -
replacing the runs-on and python-version parameters
to refer to the values from the matrix.
So, our .github/workflows/main.yml should look like the following:
...
# now define a single job 'build' (but could define more)
jobs:
build:
strategy:
matrix:
os: [ubuntu-latest, macos-latest, windows-latest]
python-version: ["3.10", "3.11"]
runs-on: ${{ matrix.os }}
...
# a job is a seq of steps
steps:
# Next we need to checkout out repository, and set up Python
# A 'name' is just an optional label shown in the log - helpful to clarify progress - and can be anything
- name: Checkout repository
uses: actions/checkout@v4
- name: Set up Python 3.11
uses: actions/setup-python@v5
with:
python-version: ${{ matrix.python-version }}
...
The ${{ }} are used as a means to reference configuration values from the matrix.
This way, every possible permutation of Python versions 3.10 and 3.11 with the latest
versions of Ubuntu, Mac OS and Windows operating systems will be tested and we can expect 6 build jobs in total.
Let’s commit and push this change and see what happens:
$ git add .github/workflows/main.yml
$ git commit -m "Add GA build matrix for os and Python version"
$ git push
If we go to our GitHub build now, we can see that a new job has been created for each permutation.
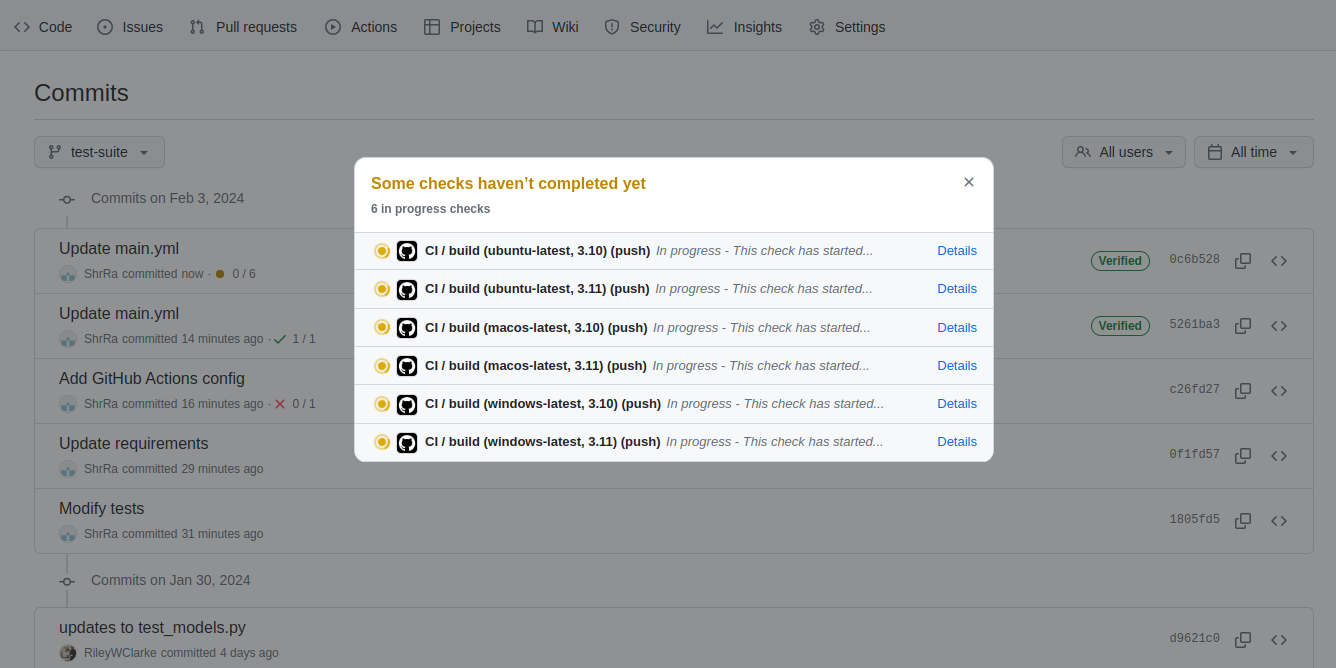
Note all jobs running in parallel (up to the limit allowed by our account) which potentially saves us a lot of time waiting for testing results. Overall, this approach allows us to massively scale our automated testing across platforms we wish to test.
Merging Back to develop Branch
Now we’re happy with our test suite, we can merge this work
(which currently only exist on our test-suite branch)
with our parent develop branch.
Again, this reflects us working with impunity on a logical unit of work,
involving multiple commits,
on a separate feature branch until it’s ready to be escalated to the develop branch:
$ git checkout develop
$ git merge test-suite
Then, assuming no conflicts we can push these changes back to the remote repository as we’ve done before:
$ git push origin develop
Now these changes have migrated to our parent develop branch,
develop will also inherit the configuration to run CI builds,
so these will run automatically on this branch as well.
This highlights a big benefit of CI when you perform merges (and apply pull requests).
As new branch code is merged into upstream branches like develop and main
these newly integrated code changes are automatically tested together with existing code -
which of course may also have changed in the meantime!
Key Points
Continuous Integration can run tests automatically to verify changes as code develops in our repository.
CI builds are typically triggered by commits pushed to a repository.
We need to write a configuration file to inform a CI service what to do for a build.
We can specify a build matrix to specify multiple platforms and programming language versions to test against
Builds can be enabled and configured separately for each branch.
We can run - and get reports from - different CI infrastructure builds simultaneously.
Verifying Code Style Using Linters
Overview
Teaching: 10 min
Exercises: 10 minQuestions
What tools can help with maintaining a consistent code style?
How can we automate code style checking?
Objectives
Use code linting tools to verify a program’s adherence to a Python coding style convention.
Introduction
One of the most important things we can do to make sure our code is readable by others (and ourselves a few months down the line) is to make sure that it is descriptive, cleanly and consistently formatted and uses sensible, descriptive names for variable, function and module names. In order to help us format our code, we generally follow guidelines known as a style guide. A style guide is a set of conventions that we agree upon with our colleagues or community, to ensure that everyone contributing to the same project is producing code which looks similar in style. While a group of developers may choose to write and agree upon a new style guide unique to each project, in practice many programming languages have a single style guide which is adopted almost universally by the communities around the world. In Python, although we do have a choice of style guides available, the PEP 8 style guide is most commonly used. PEP here stands for Python Enhancement Proposals; PEPs are design documents for the Python community, typically specifications or conventions for how to do something in Python, a description of a new feature in Python, etc. A full list of style guidelines for this style is available from the PEP 8 website. These guidelines cover naming of different types of objects, rules for indentation, recommended line lengths and so on.
Verifying Code Style Using Linters
Knowing the rules of code formatting helps us avoid mistakes
during development, so it is always a good idea to dedicate
some time to learn how to write PEP8-consistent code from the beginning.
However, we also have tools that help us with formatting
the already existing code. These tools are called
code linters,
and their main function is to identify consistency issues in a report-style.
Linters analyse source code to identify and report on stylistic and even programming errors.
For Jupyter Lab, a number of linters (as well as other tools for improving the quality of
your code) are available as part of a package called nbQA.
Let’s look at a very well-used one of these called pylint.
First, let’s create a new branch and call it style-fixes.
$ git checkout -b style-fixes
Make sure that you have activated your venv environment, and install the nbQA
package together with the supported tools:
$ python -m pip install -U nbqa
$ python -m pip install -U "nbqa[toolchain]"
We should also update our requirements.txt with this new addition:
$ pip3 freeze > requirements.txt
Using Pylint on the Notebooks
Now we can use Pylint to check the quality of our code. Pylint is a command-line tool that can help our code in many ways:
- Check PEP8 compliance: Pylint will provide a full list of places where your code does not comply with PEP8
- Perform basic error detection: Pylint can look for certain Python type errors
- Check variable naming conventions: Pylint often goes beyond PEP8 to include other common conventions, such as naming variables outside of functions in upper case
- Customisation: you can specify which errors and conventions you wish to check for, and those you wish to ignore
Pylint can also identify code smells.
How Does Code Smell?
There are many ways that code can exhibit bad design whilst not breaking any rules and working correctly. A code smell is a characteristic that indicates that there is an underlying problem with source code, e.g. large classes or methods, methods with too many parameters, duplicated statements in both if and else blocks of conditionals, etc. They aren’t functional errors in the code, but rather are certain structures that violate principles of good design and impact design quality. They can also indicate that code is in need of maintenance and refactoring.
The phrase has its origins in Chapter 3 “Bad smells in code” by Kent Beck and Martin Fowler in Fowler, Martin (1999). Refactoring. Improving the Design of Existing Code. Addison-Wesley. ISBN 0-201-48567-2.
Pylint recommendations are given as warnings or errors,
and Pylint also scores the code with an overall mark.
We can look at a specific file (e.g. light-curve-analysis.ipynb),
or a package (e.g. lcanalyzer).
First, let’s look at our notebook:
$ nbqa pylint light-curve-analysis.ipynb --disable=C0114
The --disable=C0114 parameter tells pylint to not notify us about
missing docstrings for the modules.
The output will look somewhat similar to this:
************* Module light-curve-analysis
light-curve-analysis.ipynb:cell_7:3:0: C0301: Line too long (115/100) (line-too-long)
light-curve-analysis.ipynb:cell_1:0:0: C0103: Module name "light-curve-analysis" doesn't conform to snake_case naming style (invalid-name)
light-curve-analysis.ipynb:cell_6:1:0: W0104: Statement seems to have no effect (pointless-statement)
light-curve-analysis.ipynb:cell_1:3:0: W0611: Unused numpy imported as np (unused-import)
-----------------------------------
Your code has been rated at 6.92/10
Your own outputs of the above commands may vary depending on how you have implemented and fixed the code in previous exercises and the coding style you have used.
The five digit codes, such as C0103, are unique identifiers for warnings,
with the first character indicating the type of warning.
There are five different types of warnings that Pylint looks for,
and you can get a summary of them by doing:
$ pylint --long-help
Near the end you’ll see:
Output:
Using the default text output, the message format is :
MESSAGE_TYPE: LINE_NUM:[OBJECT:] MESSAGE
There are 5 kind of message types :
* (C) convention, for programming standard violation
* (R) refactor, for bad code smell
* (W) warning, for python specific problems
* (E) error, for probable bugs in the code
* (F) fatal, if an error occurred which prevented pylint from doing
further processing.
So for an example of a Pylint Python-specific warning,
see the “W0611: Unused numpy imported as np (unused-import)” warning.
Now we can use Pylint for checking our .py files. We can do it in one go,
checking the lcanalyzer package at once.
From the project root do:
$ pylint lcanalyzer
Note that this time we use pylint as a standalone, without nbqa, since
we are analysing ordinary Python files, not notebooks.
You should see an output similar to the following:
************* Module lcanalyzer
lcanalyzer/__init__.py:1:0: C0304: Final newline missing (missing-final-newline)
************* Module lcanalyzer.models
lcanalyzer/models.py:6:0: C0301: Line too long (107/100) (line-too-long)
lcanalyzer/models.py:41:0: W0105: String statement has no effect (pointless-string-statement)
lcanalyzer/models.py:12:0: W0611: Unused LombScargle imported from astropy.timeseries (unused-import)
************* Module lcanalyzer.views
lcanalyzer/views.py:5:0: C0303: Trailing whitespace (trailing-whitespace)
lcanalyzer/views.py:15:38: C0303: Trailing whitespace (trailing-whitespace)
lcanalyzer/views.py:21:0: C0304: Final newline missing (missing-final-newline)
lcanalyzer/views.py:6:0: C0103: Function name "plotUnfolded" doesn't conform to snake_case naming style (invalid-name)
lcanalyzer/views.py:4:0: W0611: Unused pandas imported as pd (unused-import)
------------------------------------------------------------------
Your code has been rated at 6.09/10 (previous run: 6.09/10, +0.00)
It is important to note that while tools such as Pylint are great at giving you a starting point to consider how to improve your code, they won’t find everything that may be wrong with it.
How Does Pylint Calculate the Score?
The Python formula used is (with the variables representing numbers of each type of infraction and
statementindicating the total number of statements):10.0 - ((float(5 * error + warning + refactor + convention) / statement) * 10)Note whilst there is a maximum score of 10, given the formula, there is no minimum score - it’s quite possible to get a negative score!
Exercise: Further Improve Code Style of Our Project
Select and fix a few of the issues with our code that Pylint detected. Make sure you do not break the rest of the code in the process and that the code still runs. After making any changes, run Pylint again to verify you’ve resolved these issues.
Make sure you commit and push requirements.txt
and any file with further code style improvements you did
and merge onto your development and main branches.
$ git add requirements.txt
$ git commit -m "Added Pylint library"
$ git push origin style-fixes
$ git checkout develop
$ git merge style-fixes
$ git push origin develop
$ git checkout main
$ git merge develop
$ git push origin main
Auto-Formatters for the Notebooks
While Pylint provides us with a full report of all kinds of style inconsistencies,
most of which have to be fixed manually, some style mistakes can be fixed automatically.
For this, we can use
black package, also integrated in the
nbQA.
Save and close your notebook, and then go back to the command line.
After running the following command:
$ nbqa black light-curve-analysis.ipynb
Open the notebook again, you will see that black forced line wrap at a certain length of the
line, fixed duplicated or missing spaces around parenthesis or commas, aligned elements
in the definitions of lists and dictionaries and so on. Using black, you can enforce the same
style all over your code and make it much more readable.
Another Way to Use Auto-Formatter
You can use
blacknot only from the command line but from within Jupyter Lab too. For this you will need to install additional extensions, for example, Code Formatter extension. The installation, as usual, can be done usingpip:$ python -m pip install jupyterlab-code-formatterAfter that you need to refresh your Jupyter Lab page. In notebook tabs, a new button will appear at the end of the top panel. By clicking this button, you will execute the
blackformatter over the notebook.Don’t forget to commit your changes!
Adding pylint to the CI build
It may be hard to remember to run linter tools every now and then.
Luckily, we can now add this Pylint execution to our continuous integration builds
as one of the extra tasks.
Since we’re adding an extra feature to our CI workflow,
let’s start this from a new feature branch from the develop branch:
$ git checkout develop
$ git branch pylint-ci
$ git checkout pylint-ci
Then to add Pylint to our CI workflow,
we can add the following step to our steps in .github/workflows/main.yml:
...
- name: Check .py style with Pylint
run: |
python3 -m pylint --fail-under=0 --reports=y lcanalyzer
- name: Check .ipynb style with Pylint
run: |
python3 -m nbqa pylint --fail-under=0 light-curve-analysis.ipynb --disable=C0114
...
Note we need to add --fail-under=0 otherwise
the builds will fail if we don’t get a ‘perfect’ score of 10!
This seems unlikely, so let’s be more pessimistic.
We’ve also added --reports=y which will give us a more detailed report of the code analysis.
Then we can just add this to our repo and trigger a build:
$ git add .github/workflows/main.yml
$ git commit -m "Add Pylint run to build"
$ git push
Then once complete, under the build(s) reports you should see an entry with the output from Pylint as before, but with an extended breakdown of the infractions by category as well as other metrics for the code, such as the number and line percentages of code, docstrings, comments, and empty lines.
So we specified a score of 0 as a minimum which is very low. If we decide as a team on a suitable minimum score for our codebase, we can specify this instead. There are also ways to specify specific style rules that shouldn’t be broken which will cause Pylint to fail, which could be even more useful if we want to mandate a consistent style.
We can specify overrides to Pylint’s rules in a file called .pylintrc
which Pylint can helpfully generate for us.
In our repository root directory:
$ pylint --generate-rcfile > .pylintrc
Looking at this file, you’ll see it’s already pre-populated.
No behaviour is currently changed from the default by generating this file,
but we can amend it to suit our team’s coding style.
For example, a typical rule to customise - favoured by many projects -
is the one involving line length.
You’ll see it’s set to 100, so let’s set that to a more reasonable 120.
While we’re at it, let’s also set our fail-under in this file:
...
# Specify a score threshold to be exceeded before program exits with error.
fail-under=0
...
# Maximum number of characters on a single line.
max-line-length=120
...
Don’t forget to remove the --fail-under argument to Pytest
in our GitHub Actions configuration file too,
since we don’t need it anymore.
Now when we run Pylint we won’t be penalised for having a reasonable line length. For some further hints and tips on how to approach using Pylint for a project, see this article.
Before moving on, be sure to commit all your changes
and then merge to the develop and main branches in the usual manner,
and push them all to GitHub.
Key Points
Use linting tools in the IDE or on the command line (or via continuous integration) to automatically check your code style.
Measuring time and computational resources required by the software
Overview
Teaching: 15 min
Exercises: 10 minQuestions
What is software profiling?
What tools can we use to measure time and computational resources required by our software?
Objectives
Use Jupyter magics and SnakeViz to profile time and computational resources.
What is Software Profiling?
We may have a software that is doing everything that we want it to do, with its codebase well-written and perfectly comprehensible, but this does not yet guarantee that this software will be applicable to the real-world problems. For example, its interface can be so convoluted that the user can’t figure out how to access the feature of interest. Other common issue is when the software has such high computational complexity that it can be used only on small datasets, or on computer clusters with hundreds of GB of memory.
The process of estimating how much time the execution of the software will take and how much memory or other resources it will need is called profiling. Profiling is a form of dynamic program analysis, meaning that it requires launching the software and measuring its performance and logging its activity as it runs. One of the main purposes of profiling is to identify bottlenecks, inefficient operations, or high-latency components of the program, so that these parts could be optimized to run faster or to use less resources. It is worth noting that for many problems there is a space-time tradeoff, which essentially means that by optimizing the program in respect to the execution time we make it less memory-efficient, and vice versa.
How necessary profiling is for academic software development? Well, it is ok to skip profiling when working on small projects that can be easily executed on your PC or within a Google Colab notebook. However, as your projects get larger, the execution of your code may start taking days and weeks, or it may start crashing due to the lack of RAM or CPU power. Another example when the efficiency is crucial is executing your code at astronomical data access portals, such as Rubin Science Platform or Astro Data Lab. These platforms provide an opportunity to work with large astronomical datasets without downloading them to your machine, however, the CPU and memory allocated to each user are limited. Code profiling helps us to determine which implementation is more efficient and to make our code scalable. And if you are developing software that will be used by someone else, it also makes the users happier (and in some cases ensures that the software will be used at all).
In this introduction to profiling we mostly concentrate on time profiling, with some notes on memory profiling. We start with the Jupyter built-in tool, Jupyter Magics.
What Are Jupyter Magics?
Jupyter Magics are special commands in Jupyter Notebooks/Lab that extend functionality by providing shortcuts for tasks like timing, debugging, profiling, or interacting with the system, e.g. executing terminal commands from withing the notebook. They come in two forms:
- Line Magics: Prefixed with
%, they operate on a single line of code. - Cell Magics: Prefixed with
%%, they apply to the entire cell.
Why Magics aren’t really part of the Jupyter
To be specific, Magic commands are part of the Python kernels that are used by the Jupyter Notebook or Lab. The kernels are separate processes, language-specific computational engines that are executing the commands you gave it with the code. The kernel with which your notebooks is launched is separate from the frontend processes that handle, for example, the tasks of adding or removing cells, or even rendering the characters when you type them during the execution of the previous cell. Think on how different it is from when you launch some commands in your PC terminal: there, you cannot type the next commands until the previous one finish executing. The separation of the Jupyter frontend from the kernel is what allows to avoid this behavior.
By default, Jupyter uses ipykernel, and Magic commands are a part of it. However, many different kernels for Jupyter exist, including some developed for other languages, such as R or Julia. Whether Magic commands are available for these kernels depends on their implementation.
If you want to know more how kernels work, here is a generic overview with some practical examples.
There are plenty Magics cheatsheets online, however, the easiest way to look up what kinds of comands are there is to use Magics itself:
%lsmagic- prints a list of all Magics available;%quickref- prints a reference card on the available Magic commands.
Time Profiling with Magics
For time profiling, the most useful Magics are:
%time: Measures execution time of a single line.%%time: Measures execution time of an entire cell.%timeit: Repeats timing of a line for reliable results.%%timeit: Repeats timing of a cell for average results.
Let’s use this function to profile some code. As an example we’ll use a code that calculates the first thousand of partial sums of series of natural numbers and saves it into a list.
First, we need to create a new branch:
$ git checkout develop
$ git checkout -b profiling
Then let’s write one possible implementation of the code for the problem above:
%%time
# Example: Timing a block of code
result = []
for i in range(1000):
result.append(sum(range(i)))
This code creates an empty list result, and then launches a for loop in which for each i in the range from 0 to 1000
a sum of all numbers from 0 to i is calculated and appended to the list. This code produces the following output:
CPU times: user 10.4 ms, sys: 0 ns, total: 10.4 ms
Wall time: 10.2 ms
As you can notice, there are several measurements taken:
- Wall Time: Total elapsed time from start to end of a task, including waiting time for I/O operations or other processes.
- CPU Time: The time the CPU spends executing the code, further divided into User Time (time spent executing user code) and System Time (time spent on system-level operations, such as I/O or memory management).
- In general, there is also Overhead, which is the additional time introduced by profiling tools themselves, which may slightly skew results.
The double %% symbol means that %%time is applied to entire cell. Pay attention
that if you use %time instead, the result will be very different:
CPU times: user 2 μs, sys: 0 ns, total: 2 μs
Wall time: 4.05 μs
2 microseconds (since it’s μs and not ms) instead of ten milliseconds. These microseconds is the measurement of an execution time of an empty line,
since %time command does not care about the code in the following lines.
If you launch the code above several times, you’ll notice that the measured time can differ quite a lot.
Depending on the specifics of the code and on the usage of system resources by other processes,
the runtime of a code block may vary. As a side-remark, if you develop code running on a spacecraft,
you want to avoid unpredictable runtime at all cost. To get a better measurement,
%timeit and %%timeit runs the code seven times and produces mean and standard deviation of the execution time. This command
also discards outlying measurements that are likely caused by temporary system slowdowns (e.g. caused by other software that is running on your PC).
%%timeit
# Example: Timing a block of code with 'timeit'
result = []
for i in range(1000):
result.append(sum(range(i)))
4.43 ms ± 35.2 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
The 7 runs, 100 loops each tells us that the code was executed 7x100 times in total. While 7 runs is the set default value, the number of the loops
is calculated automatically depending on how fast your code is, so that profiling didn’t take too much time. You can change the number of
runs and loops using the flags -n and -r, for example, like this: %%timeit -n 4 -r 10 to run the code 4 times, with 10 loops in each run.
Another useful flag is -o that allows you to store the result of the profiling in a variable:
%%timeit -n 4 -r 10 -o
# Example: Timing a block of code with saving the profiling result
result = []
for i in range(1000):
result.append(sum(range(i)))
# In a new cell we save the content of the temporary
# variable '_' into a new variable 'measure'
measure = _
measure
<TimeitResult : 5.16 ms ± 1.56 ms per loop (mean ± std. dev. of 10 runs, 4 loops each)>
measure variable is a TimeitResult object that has some useful methods that allow us to see e.g. the value of the worst measurement
and the measurements of all runs.
Memory Profiling with Magics
On machines with limited RAM, we could also consider profiling memory usage. For this we can install more magic commands, e.g. from Python Package Index
$ python -m pip install ipython-memory-magics
and load the external memory magic via
%load_ext memory_magics
Now we can analyze the memory usage in our cell
%%memory
# Example: Memory usage
result = []
for i in range(1000):
result.append(sum(range(i)))
The output of this should look as follows:
RAM usage: cell: 35.62 KiB / 35.79 KiB
This reports current and peak memory usage of the code. Another useful
option is to use %memory -n command in an empty cell, which will print how much RAM the whole current notebook
is taking.
RAM usage: notebook: 158.61 MiB
Execution time with Magics
Use Magic commands to measure execution time for functions
max_magandplot_unfolded.Solution
Either in a new section of the
light-curve-analysis.ipynbnotebook or in a new notebook we can import themax_magfunction and use%timecommand:from lcanalyzer.models import max_mag ... %time lcmodels.max_mag(lc[lc_bands_masks[b]],mag_col=mag_col)CPU times: user 1.94 ms, sys: 155 μs, total: 2.1 ms Wall time: 1.9 ms np.float64(18.418037351622612)And we see that this command takes only a few microseconds to run. Pay attention that in order for this command to work, it should be in the same line as the code you are profiling. Otherwise, you need to use a cell Magic preceded by
%%.Next use
%timeiton a plotting function:%timeit views.plot_unfolded(lc[lc_bands_masks[b]],time_col=time_col,mag_col=mag_col,color=plot_filter_colors[b],marker=plot_filter_symbols[b])347 ms ± 9.54 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)Wow, what happened? We got seven copies of the same plot! This is because
%timeitrepeats the execution and measures the average time. Plotting also takes noticeably longer time that a simple calculation of a maximum value.
A Few Words on Optimization
Let’s take our ‘partial sums of series’ problem and think on how we can optimize it to run faster.
You may remember that Python has list comprehensions
syntax that is often recommended as a faster tool than for loops. We can rewrite the code above to use list comprehensions
and use %%timeit magic to profile it.
%%timeit
# Implementation with list comprehension
result = [sum(range(i)) for i in range(1000)]
4.43 ms ± 71 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Well… Actually, we got pretty much the same result. For this particular case, there is no computational
gain in using list comprehension, although the code is cleaner and more readable this way. However, if we experiment
with the maximum value of the range, we’ll start noticing the gain with the increase of this value. That said,
for some problems list comprehensions may work even slower than for loops, which is why time profiling
is something to do before you start optimization - it may turn out that the bottleneck is in a completely different
part of the program than you thought. In order to optimise this specific piece of code, we would have to be
smarter and use an equation instead of the bruteforce approach:
%%timeit
# Optimized implementation using mathematical formula for summation
result = [(i * (i - 1)) // 2 for i in range(1000)]
77.6 μs ± 812 ns per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
Now the execution time is in dozens of microseconds, which is two orders better than before! That’s quite an improvement.
What If You Don’t Use Jupyter?
Of course, Jupyter Magics isn’t the only tool for time profiling. In fact, Python has built-in modules just for this, such as time and timeit,
that can be used in any IDE.
import time
...
start_time = time.time()
max_mag = lcmodels.max_mag(lc[lc_bands_masks[b]],mag_col=mag_col)
print(f"Execution time: {time.time() - start_time:.5f} seconds")
Execution time: 0.00083 seconds
In this snippet of code, time.time() function records the current time in seconds since the epoch (typically January 1, 1970).
This value is stored in the variable start_time before the code block is executed.
After the code block, time.time() is called again to get the current time.
The difference between the current time and start_time gives the total execution time.
This elapsed time is formatted to five decimal places and printed. The time
library is useful also in notebooks, when we want to get a detailed execution time log from the inside
of a larger piece of code, e.g. a function.
To get a more reliable estimate, for the small snippets of code we can use timeit.repeat() method.
It executes the timing multiple times and provides a list of results, making it easier to analyze performance under changing environments.
import timeit
results = timeit.repeat('sum([i**2 for i in range(1000)])', repeat=5, number=1000)
print("Timing Results:", results)
print("Best Execution Time:", min(results))
Timing Results: [0.17868508584797382, 0.16405000817030668, 0.16924912948161364, 0.1637995233759284, 0.16636504232883453]
Best Execution Time: 0.1637995233759284
The repeat and number parameters of this function work similarly to the number of runs and number of loops for the %%timeit.
However, this method cannot be used conveniently for e.g. measuring execution time of functions. For this, we need a more advanced tool.
Additional reading on ‘time’ module and
Some additional sources to look into are:
- Python timeit Module: Detailed explanation of how to use the
timeitmodule for benchmarking Python code.- Python time Module: Overview of the
timemodule, including functions liketime(),sleep(), and more.- Profiling in Python: A beginner-friendly introduction to time profiling methods in Python.
Resource profiling with offline profilers
Jupyter Magics, while extremely useful for small-scale profiling, aren’t a suitable tool for larger projects. Prioritizing development requires to understand multiple aspects of the code ‘under-the-hoods’:
- The frequency at which a function is called,
- The execution time for each function,
- The performance of different algorithms,
- Benchmarking pure python vs external C code,
- Identify bottlenecks and gauge how involved a change is compared to the development effort.
There are numerous tools for these inquiries. Here we will consider the cProfile and
snakeviz modules.
cProfile is a built-in Python module that measures how many times each function was called from within the code
that is being profiled and how much time the execution of each function took. cProfile is partially written in C, which makes it faster
and reduces the overhead that is inevitably added by any profiler. If cProfile doesn’t work on your PC, you can try to use pure Python version
of this module called profile.
cProfile can be imported like any other package, and then used to profile any code by passing it in quotation marks to the function run:
import cProfile
profiler = cProfile.Profile()
profiler.run('[sum(range(i)) for i in range(10000)]')
profiler.print_stats(sort='cumulative')
10004 function calls in 0.616 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.616 0.616 {built-in method builtins.exec}
1 0.000 0.000 0.616 0.616 <string>:1(<module>)
1 0.007 0.007 0.616 0.616 <string>:1(<listcomp>)
10000 0.609 0.000 0.609 0.000 {built-in method builtins.sum}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
First we are initializing a Profile() instance, then we execute the profiling, and then printing the output sorted
by the cumulative time spent in each of the funtions. The columns in this statistical table report how many times
each functon was called (ncalls; we can see that in this example the only function with multiple calls in sum), how much time in
total was spent in each function (tottime; it does not take into account the time spent in sub-functions), average time per each call (percall),
how much time was spent in this function taking into account sub-functions (cumtime) and average time per call considering sub-calls (second percall).
We sorted this output by the cumtime column, however, if we change sorting to tottime, we’ll see that most of the time was spent in the sum functions.
Which is not surprising, considering that we made a 10000 calls of this function!
Visualizing Profiling Output with SnakeViz
An output table of cProfile can be really large and confusing. It would be nice to have a visual representation of this data.
Fortunately, there is a tool for this, a module called snakeviz.
First let’s install it and update the requirements.txt file:
$ python -m pip install snakeviz
$ pip freeze > requirements.txt
In order to use it from within the notebook, we have to load it as an external magic:
%load_ext snakeviz
%snakeviz res=[sum(range(i)) for i in range(10000)]

Now we have a nice interactive representation of the time spent in each function, and it is obvious that the summation itself takes the longest.
We can choose between two formats of the visualization using ‘Style’ drop-down menu, set the maximum depth of the call stack that is being visualized and
set the cutoff value for the functions that won’t be placed on the plot (e.g. by default the functions that take less than 1/1000 of the execution time
of the parent function are omitted). By clicking on any of the bars we go deeper into the callstack.
Under the plot we have the same statistical table as the cProfile produces. There is also a way to open this visualization in a new browser tab by
passing the flag -t after the command.
Other Visualization Tools for cProfile
SnakeVizisn’t the only visualization tool for profiling. You may want to look at the gprof2dot which plots call graphs in the following way, which some users could find more intuitive than the defaultsnakevizplots:
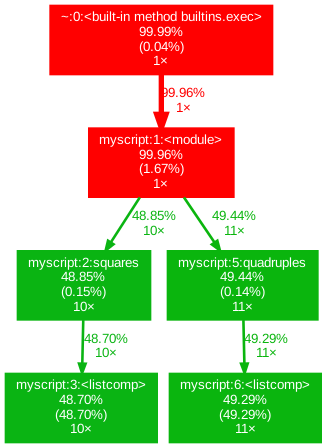
Use SnakeViz to profile the lcanalyzer.calc_stats() function and optimize it for a quicker execution
Apply the
%snakevizto the lcanalyzer.calc_stats() function. Have a look at the output, identify which functions are taking the longest to execute and optimize this code to execute faster.Solution
After running the following code:
%snakeviz calc_stats(lc_dict,bands,'psfMag'), we obtain a visualization that looks similar to this:We can notice that a lot of time is spent in the
from_recordspandascore function and__getitem__, that is invoked when we use indexing to retrieve some element from a DataFrame. Thepandasstatistical functions take approximately the same amount of time.One thing that can be done right away is reducing the number of indexing calls and switching to the
numpystatistical functions by converting our data into anumpy.array, e.g. like this:def calc_stats_nparrs(lc, bands, mag_col): # Calculate max, mean and min values for all bands of a light curve stats = {} for b in bands: arr = np.array(lc[b][mag_col]) stat = {'max':np.max(arr),'mean':np.mean(arr),'min':np.min(arr)} stats[b] = stat return statsThe profiling result for this function will look like this:
The new version of the function works almost 6 times faster, however, for this we had to change the format of the output. We could have left it as it was, but then the execution time gain would be smaller. With the current changes to the function, we have to rewrite the higher levels of the code and our tests, and, perhaps, rethink in general the data architecture of our software.
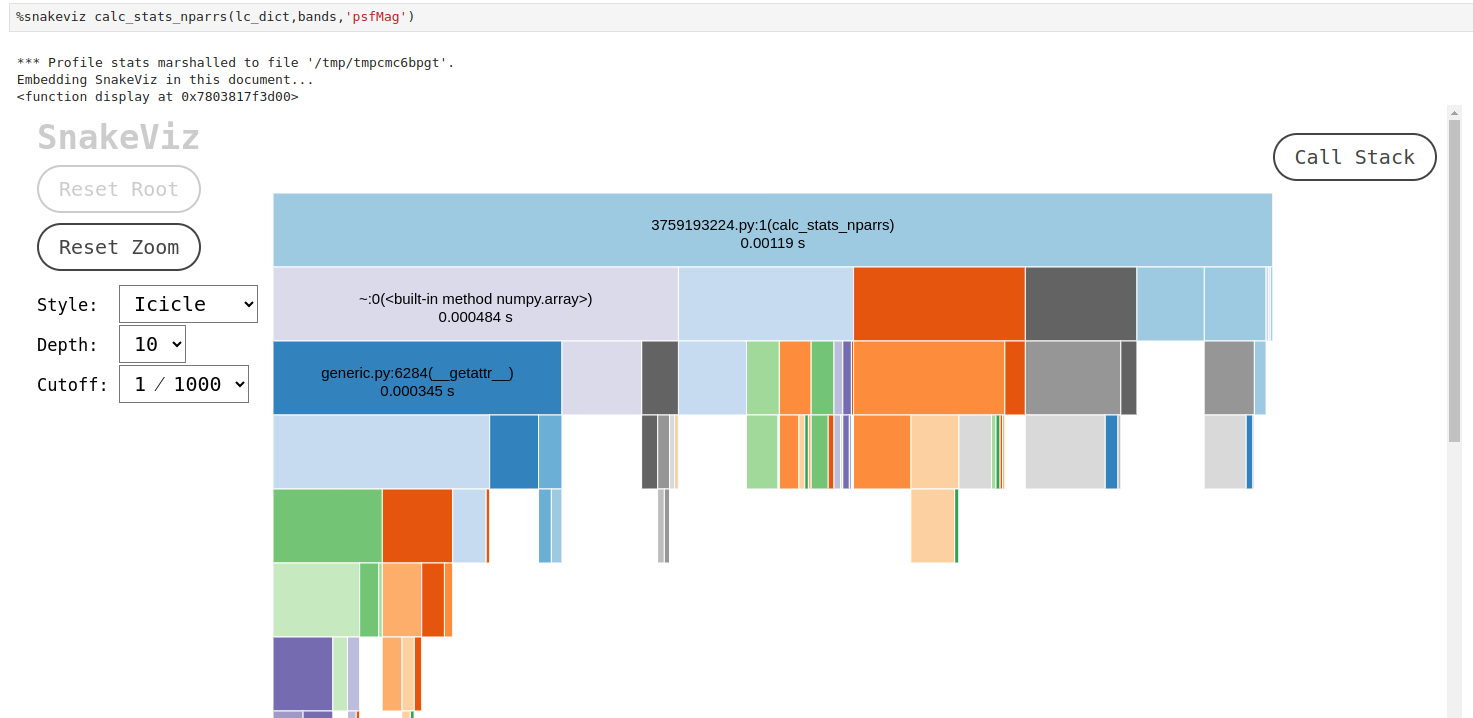
Resource profiling with online profilers
Profiling a running project can be an invaluable tool for identifying and addressing issues, as it catches unusual events that may not be obvious during development. It is possible to do a real-time performance monitoring, although the detailed info on the corresponding instruments goes beyond the scope of today’s workshop. As starting points for further reading, you can have a look at these two repositories:
Key Points
For our software to be usable, we need to take care not only of its correctness, but also of its performance.
Profiling is necessary for large computationally expensive projects or for the software that will be processing large datasets.
Finding bottlenecks and ineffective subroutines is an important part of refactoring, but it is also a useful thing to do at the stage of planning the architecture of the software.
Wrap-up
Overview
Teaching: 15 min
Exercises: 0 minQuestions
Looking back at what was covered and how different pieces fit together
Where are some advanced topics and further reading available?
Objectives
Put the course in context with future learning.
Summary
As part of this course we have looked at a core set of established, intermediate-level software development tools and best practices for ensuring that your software is correct and usable in real life. The course teaches a selected subset of skills that have been tried and tested in collaborative research software development environments, although not an all-encompassing set of every skill you might need (check some further reading). It will provide you with a solid basis for writing industry-grade code, which relies on the same best practices taught in this course.
Things like unit testing, CI and profiling play an important part of software development in large teams, but also have benefits in solo development. We’ve looked at the benefits of a well-considered development environment, using practices, tools and infrastructure to help us write code more effectively in collaboration with others.
We’ve looked at the importance of being able to verify the correctness of software and automation, and how we can leverage techniques and infrastructure to automate and scale tasks such as testing to save us time - but automation has a role beyond simply testing: what else can you automate that would save you even more time? Once found, we’ve also examined how to locate faults in our software.
Reflection Exercise: Putting the Pieces Together
As a group, reflect on what aspects of your work can benefit from applying the techniques and tools you learned during this workshop. What would be the main issues preventing these workflow changes?
Solution
One way to think about these concepts is to make a list and try to organise them along two axes - ‘perceived usefulness of a concept’ versus ‘perceived difficulty or time needed to master a concept’, as shown in the table below (for the exercise, you can make your own copy of the template table for the purpose of this exercise). You then may think in which order you want to learn the skills and how much effort they require - e.g. start with those that are more useful but, for the time being, hold off those that are not too useful to you and take loads of time to master. You will likely want to focus on the concepts in the top right corner of the table first, but investing time to master more difficult concepts may pay off in the long run by saving you time and effort and helping reduce technical debt.
Further Resources
Below are some additional resources to help you continue learning:
- Foundations of Astronomical Data Science Carpentries Workshop
- A previous InterPython workshop materials, covering collaborative usage of GitHub, Programming Paradigms, Software Architecture and many more
- CodeRefinery courses on FAIR (Findable, Accessible, Interoperable, and Reusable) software practices
- Python documentation
- GitHub Actions documentation
Key Points
Collaborative techniques and tools play an important part of research software development in teams.