Resource requirements
Overview
Teaching: 30 min
Exercises: 10 minQuestions
What is the difference between requesting for CPU and GPU resources using Slurm?
How can I optimize my slurm script to avail the best resources for my specific task?
Objectives
Understand different types of computational workloads and their resource requirements
Write optimized Slurm job scripts for sequential, parallel, and GPU workloads
Monitor and analyze resource utilization
Apply best practices for efficient resource allocation
Understanding Resource Requirements
Different computational tasks have varying resource requirements. Understanding these patterns is crucial for efficient HPC usage.
Types of Workloads
CPU-bound workloads: Tasks that primarily use computational power
- Mathematical calculations, simulations, data processing
- Benefit from more CPU cores and higher clock speeds
Real-world astronomy example:
Calculating theoretical stellar evolution tracks using the MESA code.
Each star’s model requires intense numerical integration of stellar structure equations over millions of time steps, mostly using the CPU.
Memory-bound workloads: Tasks limited by memory access speed
- Large dataset processing, in-memory databases
- Require sufficient RAM and fast memory access
Real-world astronomy example:
Processing full-sky Cosmic Microwave Background (CMB) maps from Planck at high resolution.
The HEALPix maps are large, and operations like spherical harmonic transforms require large amounts of RAM to store intermediate matrices.
I/O-bound workloads: Tasks limited by disk or network operations
- File processing, database queries, data transfer
- Benefit from fast storage and network connections
Real-world astronomy example:
Stacking thousands of raw Rubin Observatory images to improve signal-to-noise ratio for faint galaxy detection.
The bottleneck is reading the large image files from storage and writing processed results back.
GPU-accelerated workloads: Tasks that can utilize parallel processing
- Machine learning, scientific simulations, image processing
- Require appropriate GPU resources and memory
Real-world astronomy example:
Training a convolutional neural network to classify transient events in ZTF light curves.
The matrix multiplications and convolutions benefit greatly from GPU acceleration.
Types of Jobs and Resources
When you run work on an HPC cluster, your job’s type determines how it will be scheduled and what resources it will use. Broadly, jobs fall into three categories:
-
Serial jobs
These use a single CPU core (or sometimes a single thread) to run all calculations. They don’t require communication between multiple processes. They’re ideal for workloads like simple data analysis, single-threaded simulations, or testing code. -
Parallel jobs
These use multiple CPU cores — sometimes across multiple nodes — to run tasks simultaneously. Parallel jobs often use MPI (Message Passing Interface) or OpenMP explained in the previous section to coordinate work. They’re suited for large-scale simulations or computations that can be split into many parts running at once. -
GPU jobs
These use Graphics Processing Units to accelerate certain types of workloads, especially those involving heavy numerical computation like deep learning, image processing, or large matrix operations. GPU jobs often also use CPU cores for parts of the workflow.
Once you know your job type, you can select the correct SLURM partition (queue) and request the right resources:
| Job Type | SLURM Partition | Key SLURM Options | Example Use Case |
|---|---|---|---|
| Serial | computes_thin |
--partition, no MPI |
Single-thread tensor calc |
| Parallel | computes_thin |
-N, -n, mpirun |
MPI simulation |
| GPU | gpu |
--gpus, --cpus-per-task |
Deep learning training |
Choosing the Right Node
- Regular Node: For MPI-based distributed jobs or simple CPU tasks.
- SMP Node (Symmetric Multiprocessing): For jobs needing large shared memory (big matrices, in-memory data) or multi-threaded code (OpenMP, R, Python multiprocessing).
- In an SMP system, multiple CPUs (cores) share the same physical memory and can access it at the same speed. This architecture is ideal when tasks need frequent access to a common memory space without the communication overhead of distributed systems.
- GPU Node: For massively parallel computations on GPUs (e.g., CUDA, TensorFlow, PyTorch).
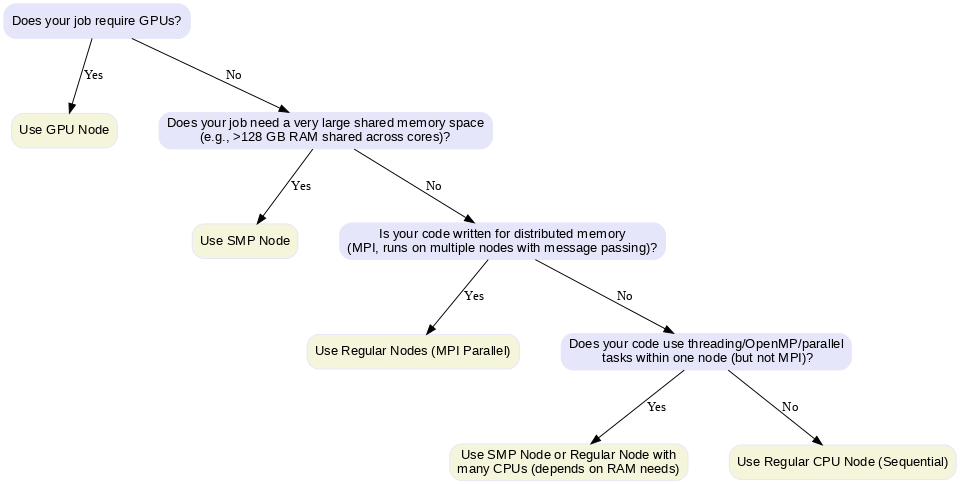
Decision chart for Choosing Nodes
Exercise: Classify the Job Type
Using the decision chart above, classify each of the following HPC tasks into CPU-bound, Memory-bound, I/O-bound, or GPU-accelerated, and suggest the most appropriate node type.
Running a grid of supernova explosion models, varying the star mass, explosion energy, circumstellar density, and radius. Each model runs independently on a separate CPU.
Simulating the galactic stellar population across many spatial grid points for the entire galactic plane. Each grid point is independent; results are aggregated at the end.
- Running the 2D-Hybrid pipeline for periodicity detection on ZTF DR6 quasar light curves:
- Processing objects in batches of 1000 per job.
- Each object is analyzed with wavelet + cross-band methods.
Simulating and fitting microlensing light curves, where each fit is run on a separate CPU, and runtime varies between light curves.
- Distributing difference imaging runs for transient detection using PyTorch, previously run on GPUs, or via MPI/HTCondor.
Discussion:
Are some tasks “mixed-type”? Which resources are more critical for performance? How would you prioritize CPU vs GPU vs memory for these workloads?Solutions
- Grid of supernova explosion models
- Type: CPU-bound (parallel)
- Reason: Each model is independent; heavy numerical computations per model.
- Node type: Regular node (multi-core CPU).
- SLURM options: Use multiple CPUs; each job in the array runs a separate model with
--array=1-100.- Galactic stellar population simulation
- Type: CPU-bound (embarrassingly parallel)
- Reason: Each spatial grid point is independent; computation-heavy but not memory-intensive.
- Node type: Regular node or multi-node if very large. CPUs are sufficient.
- SLURM options: Distribute grid points across CPU cores; use MPI or job arrays with
--ntasks=64.- 2D-Hybrid pipeline for ZTF quasar light curves
- Type: CPU-bound (parallel)
- Reason: Wavelet + cross-band analysis is CPU-only; each batch processed independently.
- Node type: Regular node (multi-core CPU).
- SLURM options: Array jobs with
--cpus-per-taskfor intra-batch parallelization.- Microlensing light curve fitting
- Type: CPU-bound (parallel, varying runtimes)
- Reason: Each light curve fit is independent; some fits take longer than others.
- Node type: Regular node or SMP node if shared memory needed for multithreaded fits.
- SLURM options: Array jobs with
--array=1-999for fitting all light curves.- Difference imaging runs with PyTorch / MPI / HTCondor
- Type: GPU-accelerated (if using PyTorch) or CPU-bound (MPI/HTCondor alternative)
- Reason: GPU use accelerates image subtraction; MPI/HTCondor distributes CPU tasks efficiently.
- Node type: GPU node (for PyTorch) or regular nodes (for MPI/HTCondor).
- SLURM options:
--gpusfor GPU tasks,-N/-nfor MPI tasks.
Key Points
Different computational models (sequential, parallel, GPU) significantly impact runtime and efficiency.
Sequential CPU execution is simple but inefficient for large parameter spaces.
Parallel CPU (e.g., MPI or OpenMP) reduces runtime by distributing tasks but is limited by CPU core counts and communication overhead.
GPU computing can drastically accelerate tasks with massively parallel workloads like grid-based simulations.
Choosing the right computational model depends on the problem structure, resource availability, and cost-efficiency.
Effective Slurm job scripts should match the workload to the hardware: CPUs for serial/parallel, GPUs for highly parallelizable tasks.
Monitoring tools (like
nvidia-smi,seff,top) help validate whether the resource request matches the actual usage.Optimizing resource usage minimizes wait times in shared environments and improves overall throughput.